GoogleがGemma 2Siriーズを発表:1つのTPUで動作可能な27Bパラメータモデルの新登場
Most people like
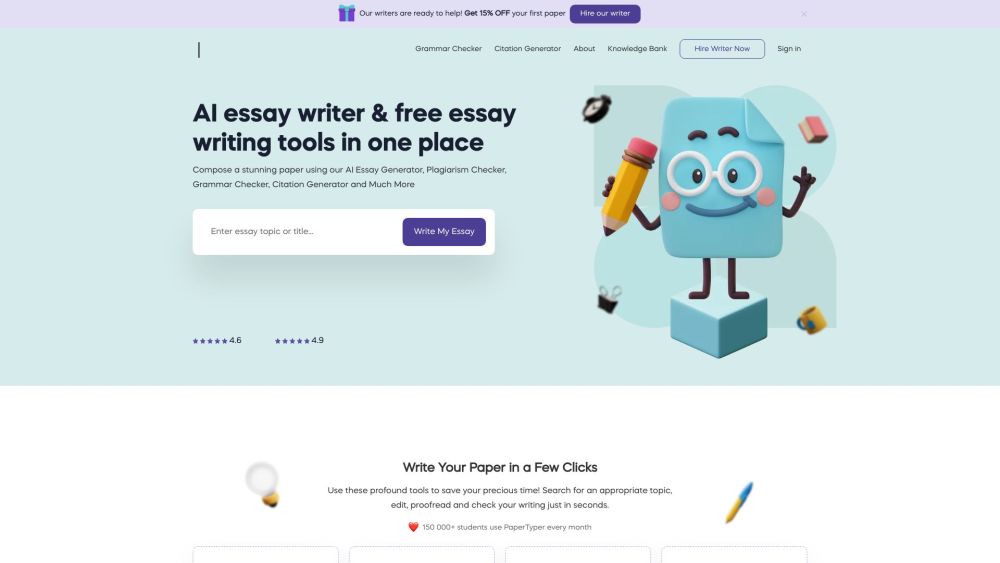
無料のオンラインツールで簡単に論文作成を始めよう
論文作成を向上させるために厳選された無料のオンラインツールをご紹介します。学術エッセイ、研究論文、クリエイティブライティングなど、さまざまなプロジェクトに対応したこれらのリソースがあれば、プロセスを効率化し、執筆の質を向上させ、生産性を高めることができます。使いやすいオンラインソリューションであなたの執筆力を引き出し、作品をレベルアップさせましょう。
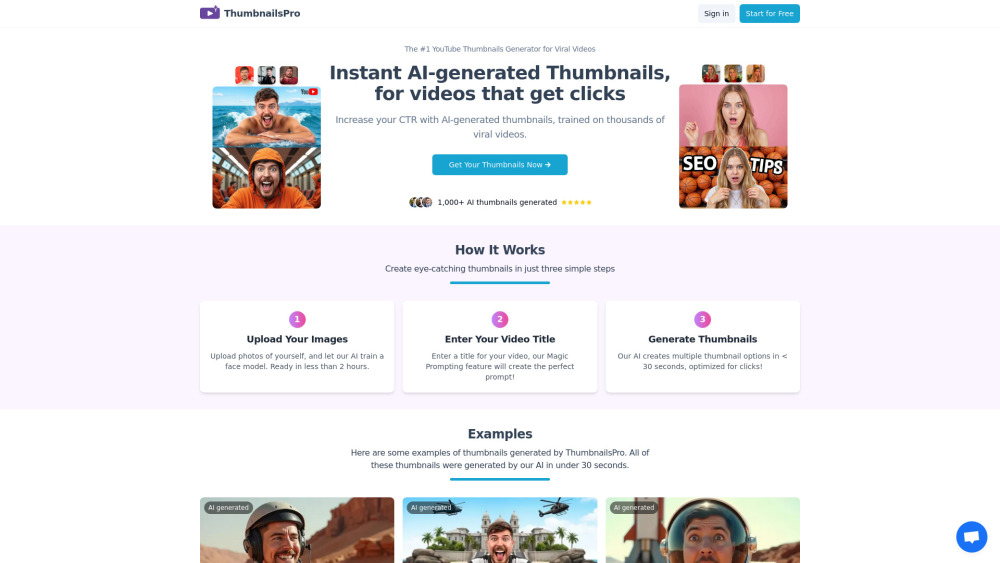
クリエイター向けに特別に設計されたAIサムネイルジェネレーターで、YouTube動画のエンゲージメントを向上させましょう。目を引くビジュアルを、視聴者を惹きつけ、クリック率を向上させる強力なツールに変身させます。

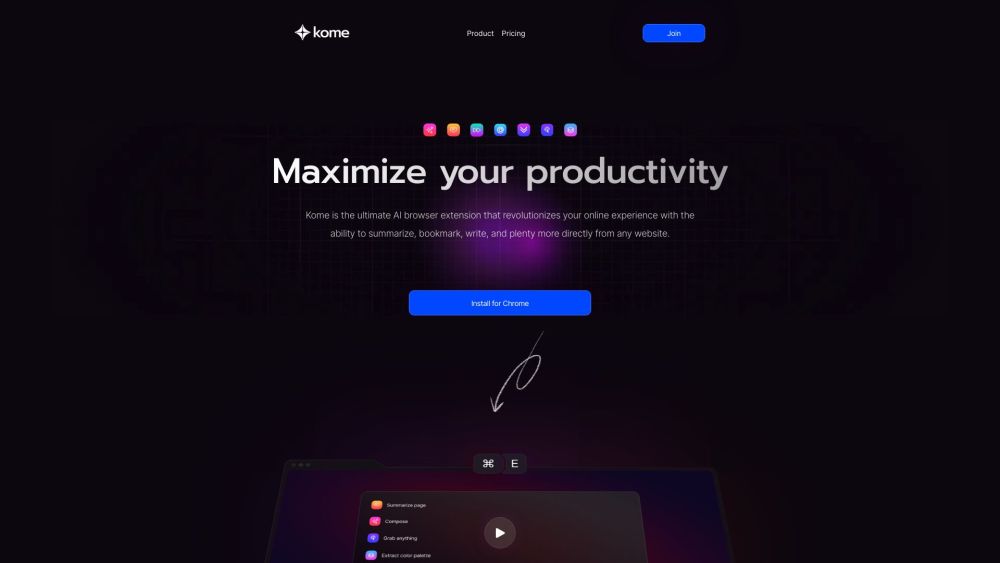
Komeは、AI駆動のツールを統合してオンラインブラウジング体験を豊かにする革新的なブラウザ拡張機能です。
Find AI tools in YBX
Related Articles
Refresh Articles