NVIDIAがLlama-3.1-Nemotron-51B AIモデルを発表:H100 GPUによる効率的コンピューティングの革新
Most people like
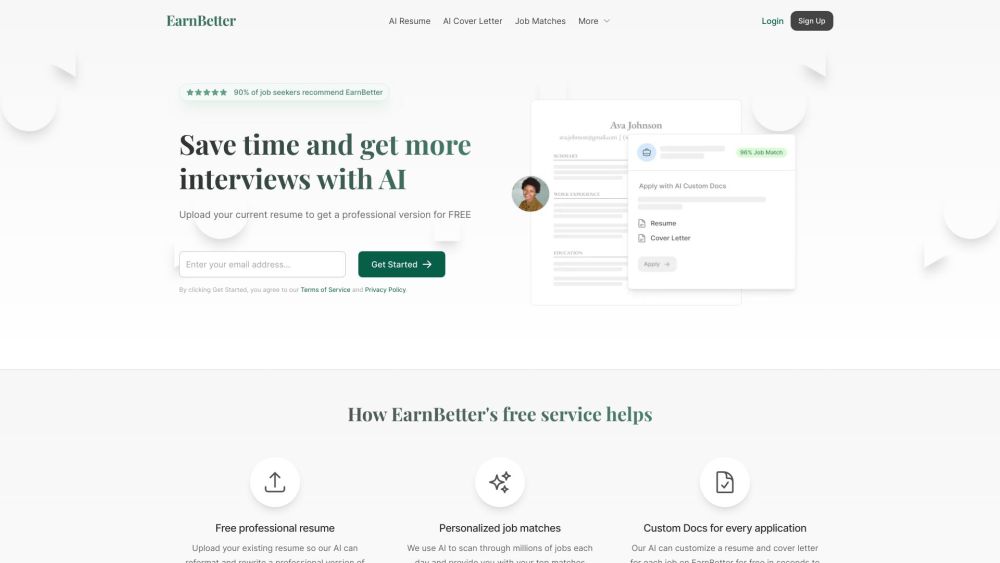
キャリアの可能性を引き出す無料のAI求人検索アシスタントをご利用ください。この革新的なツールは、パーソナライズされた推奨、カスタマイズされた履歴書の提案、面接準備のヒントを提供し、求人探しを効率化します。初めての就職を目指す方もキャリアチェンジを考えている方も、私たちのAIアシスタントはあなたのスキルや目標に合った機会と結びつけるために設計されています。今日から求人活動を最大化しましょう!
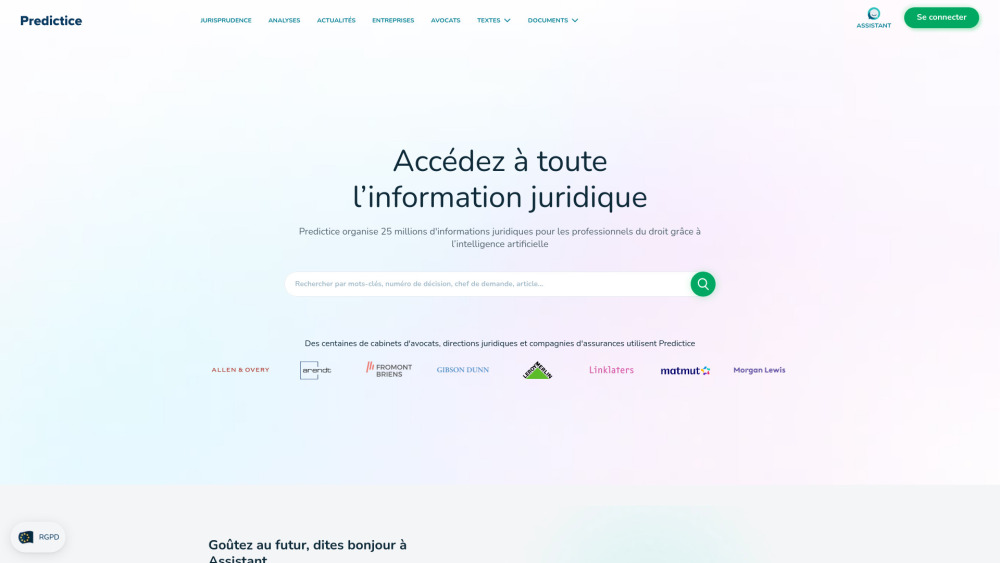
今日の急速に変化する法的環境において、法務調査の効率は極めて重要です。当社のプラットフォームは、法務専門家が文書を検索・分析する方法を革新し、直感的な機能と高度なアルゴリズムを提供してプロセスを簡素化します。洗練されたツールを使えば、ユーザーは関連する法的文書を簡単に見つけ出し、より深い洞察を得て、全体的な生産性を向上させることができます。法務実務家が容易に情報に基づいた意思決定を行える新しい法務調査の時代を体験してください。
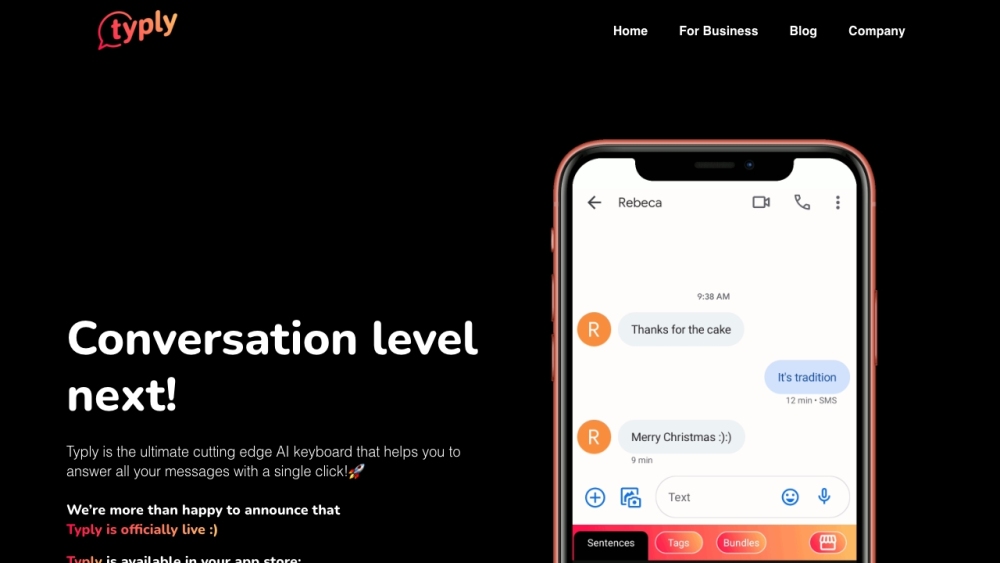
Typlyは、スマートな文の提案を通じて迅速でスムーズなコミュニケーションを実現する革新的なAI搭載キーボードです。Typlyを使えば、完璧なメッセージを作成するのがこれまでになく簡単になります!
数秒でリアルな合成音声を作成します。あなたのニーズに合わせたリアルな音声ソリューションを提供する最先端技術の力を体験してください。
Find AI tools in YBX
Related Articles
Refresh Articles