애플, 장치 내 실행을 위한 오픈 소스 AI 모델 출시
Most people like
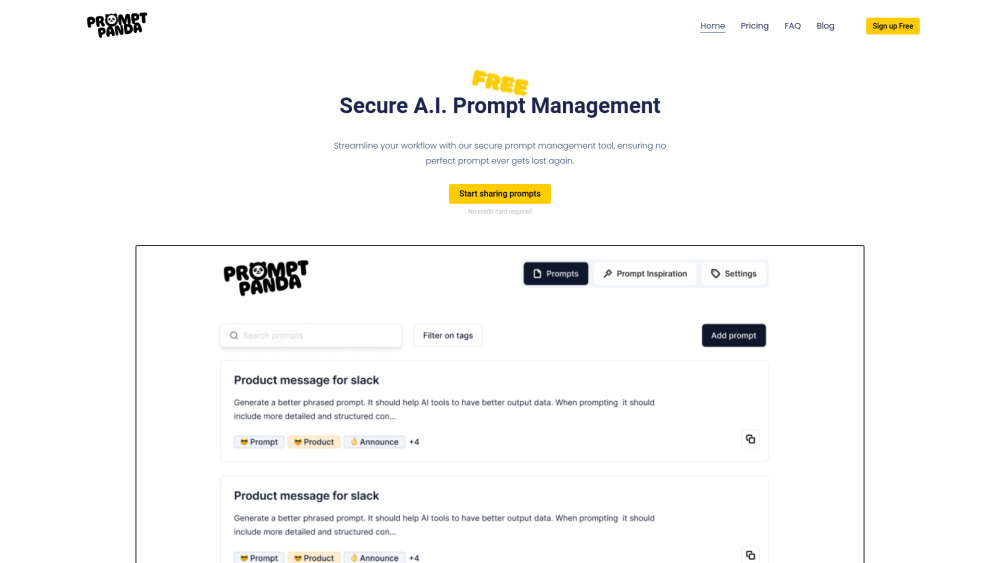
오늘날의 빠르게 변화하는 디지털 환경에서 효과적인 AI 프롬프트 관리는 워크플로우 최적화에 필수적입니다. 인공지능의 힘을 활용하면 프로세스를 간소화하고 생산성을 향상시키며 전반적인 효율성을 극대화할 수 있습니다. 이 가이드에서는 AI 프롬프트 관리를 마스터하기 위한 주요 전략과 도구를 탐구하여 귀하의 운영이 원활하고 효과적으로 진행될 수 있도록 도와드립니다.


GPU가 필요 없는 오프라인 AI 실험을 위한 혁신적인 앱을 만나보세요. 인공지능의 잠재력을 발휘하고, 언제 어디서나 이 사용자 친화적인 도구로 혁신적인 솔루션을 탐색해 보세요.
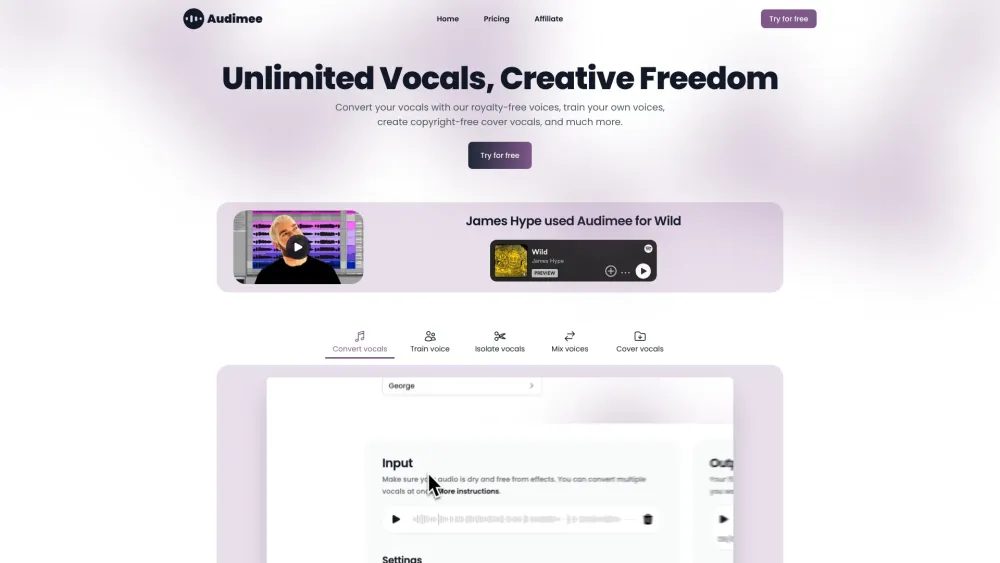
목소리의 힘을 여러분의 것으로 만들어보세요. 우리의 첨단 음성 변환 도구는 여러분의 목소리 퍼포먼스를 한층 끌어올리도록 설계되었습니다. 음악가, 팟캐스터, 콘텐츠 제작자 누구에게나 이 혁신적인 기술은 목소리를 손쉽게 변형하고 향상시킬 수 있는 기회를 제공합니다. 한계는 잊고, 사운드의 무한한 가능성을 만나보세요. 우리의 도구가 어떻게 여러분의 청중을 사로잡는 전문적인 품질의 결과를 이끌어 낼 수 있는지 알아보세요!
Find AI tools in YBX
Related Articles
Refresh Articles