Скандал вокруг бесплатного набора изображений ИИ после удаления материалов с детской сексуальной эксплуатацией
Most people like
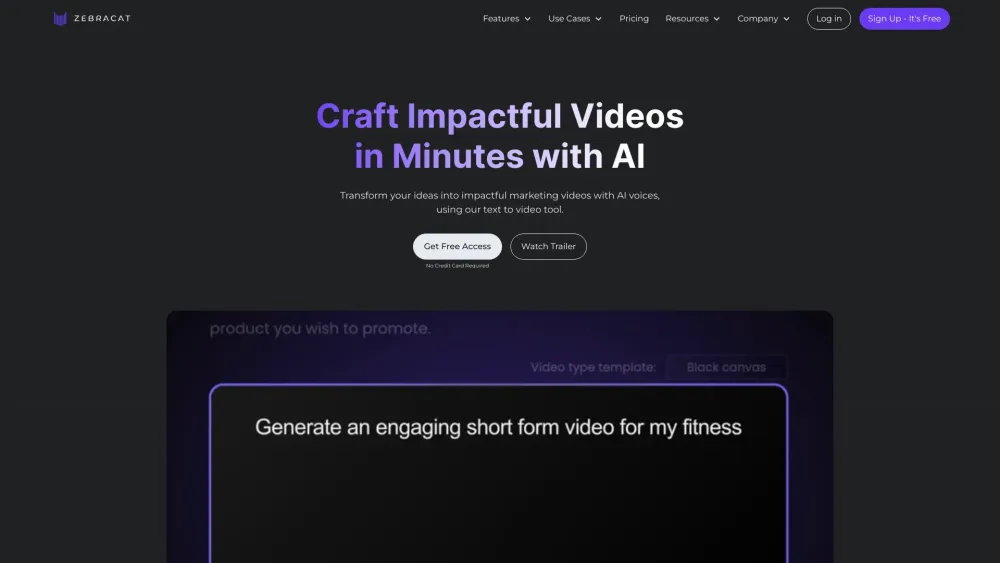
В современном цифровом мире эффективный маркетинг требует ярких визуалов, которые находят отклик у аудитории. Создание видео с использованием ИИ упрощает процесс производства качественного контента, что позволяет брендам более эффективно взаимодействовать с зрителями. Используя сложные алгоритмы и машинное обучение, компании теперь могут создавать индивидуальные видео, которые не только привлекают внимание, но и способствуют конверсиям. Узнайте, как технологии ИИ трансформируют видеомаркетинг в динамичный инструмент для роста бренда и связи с аудиторией.
Раскрытие секретов достижения результатов A* на экзаменах A Level стало более доступным, благодаря мощному пересечению ИИ и когнитивной науки. Эти передовые области предлагают инновационные стратегии и инструменты, которые улучшают обучение и запоминание, открывая путь к академическому успеху. Используя их идеи, студенты могут максимально раскрыть свой потенциал и преуспеть в учебе.
В современном цифровом пространстве поддержание актуальности и привлекательности вашего веб-сайта критически важно для привлечения и удержания посетителей. Наш инструмент редизайна веб-сайтов на основе ИИ использует передовые алгоритмы для анализа поведения пользователей и тенденций дизайна, обеспечивая бесшовный и динамичный онлайн-опыт. Это инновационное решение позволяет компаниям без усилий улучшать свое веб-присутствие, повышать вовлеченность пользователей и, в конечном итоге, увеличивать конверсии. Узнайте, как наши технологии ИИ могут преобразовать ваш веб-сайт в мощный инструмент для роста.
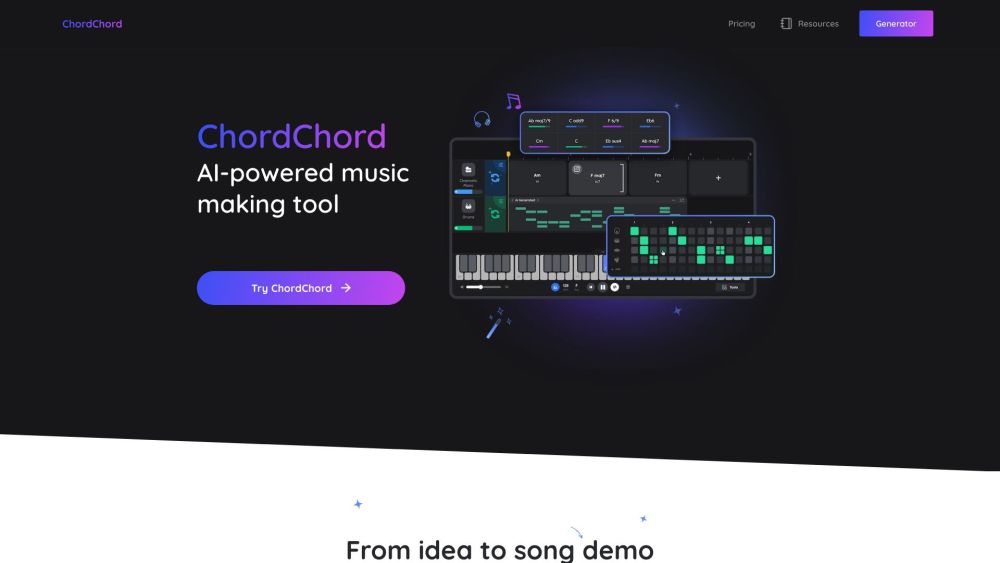
Представляем ChordChord: ваш идеальный генератор аккордов и инструмент для создания музыки! Независимо от того, являетесь ли вы опытным музыкантом или только начинаете, ChordChord упрощает создание прекрасных мелодий и исследование бесконечных музыкальных возможностей.
Find AI tools in YBX
Related Articles
Refresh Articles