全面指南:確保人工智慧系統開發的安全性
Most people like
簡化您的社交媒體策略,透過自動化影片製作。 在當今迅速變化的數位環境中,吸引人的影片內容對於抓住觀眾的注意力至關重要。自動化工具徹底改變了您製作影片的方式,使分享引人入勝的故事、展示產品和與追隨者連結變得更簡單更快速。無論您是希望增強線上形象的品牌,還是希望擴大影響力的個人創作者,都能發現自動化影片製作如何提升您的社交媒體表現。
在當今競爭激烈的市場環境中,擁有一份結構完善的商業計劃對於成功至關重要。我們的智慧型平台提供量身定制的商業計劃,滿足您的獨特需求和目標。透過先進的算法和專業見解,我們確保每份計劃不僅為您量身打造,還能與您的願景及市場需求戰略對接。體驗我們為各類型企業及創業者設計的個性化規劃解決方案的方便性與有效性。
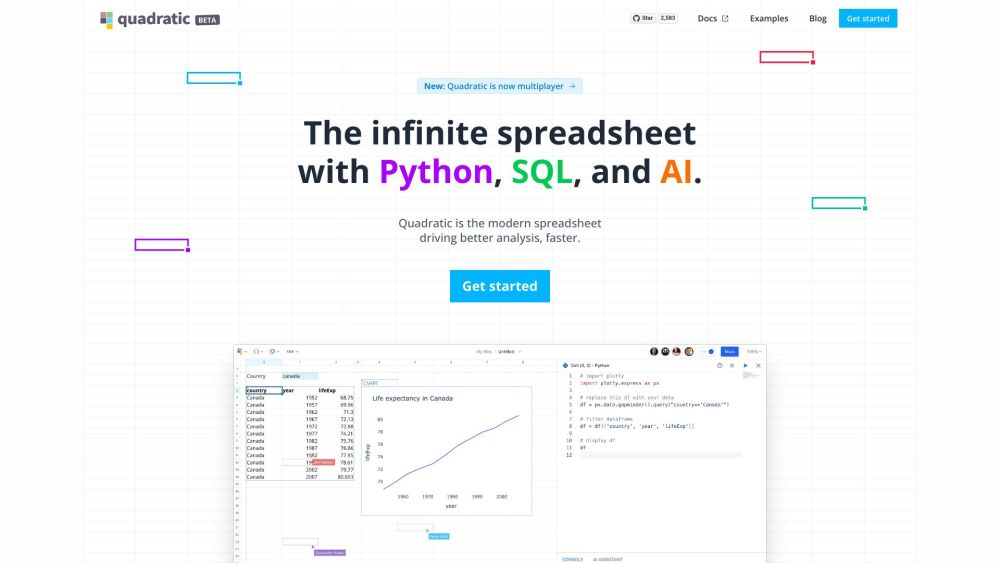
在當今快節奏的數位環境中,開發者需要高效的工具以簡化協作並提升生產力。即時電子表格提供了一個強大的解決方案,使團隊可以同時進行數據管理和分析。這種互動式的方式不僅促進了無縫的溝通,還能實現即時更新,成為開發者優化工作流程的必備資源。探索如何整合即時電子表格,提升您的專案管理和數據協作成效。
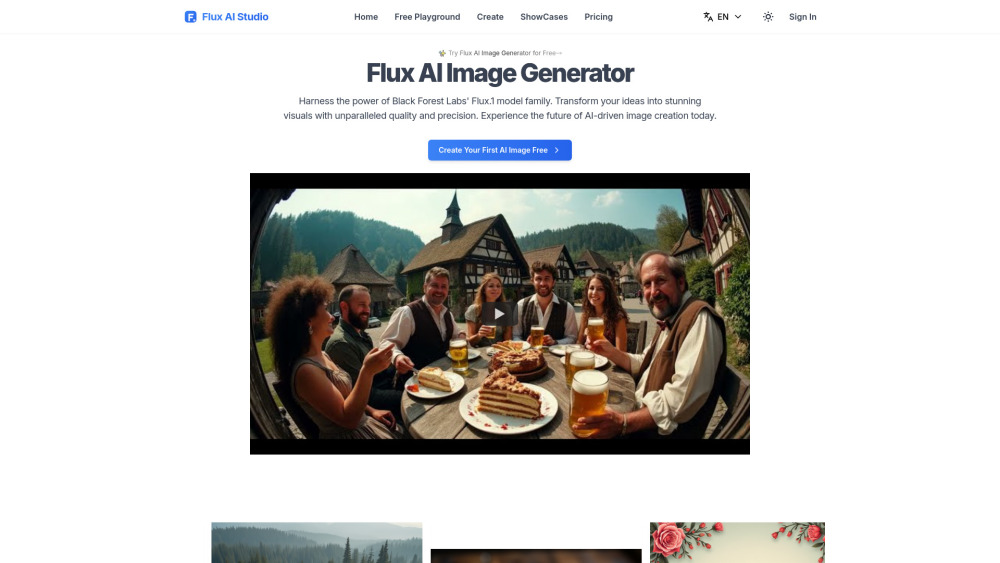
探索我們的人工智慧平台,將您的文字轉換為精美的圖像。借助先進技術,您可以輕鬆地將您的想法具象化——創造與您想像相符的視覺效果。加入無數用戶的行列,發掘將創意轉化為迷人圖像的潛力,使用我們的創新工具。
Find AI tools in YBX
Related Articles
Refresh Articles