有限的LLM訪問權限?Snowflake推出跨區域推理,提升可用性
Most people like
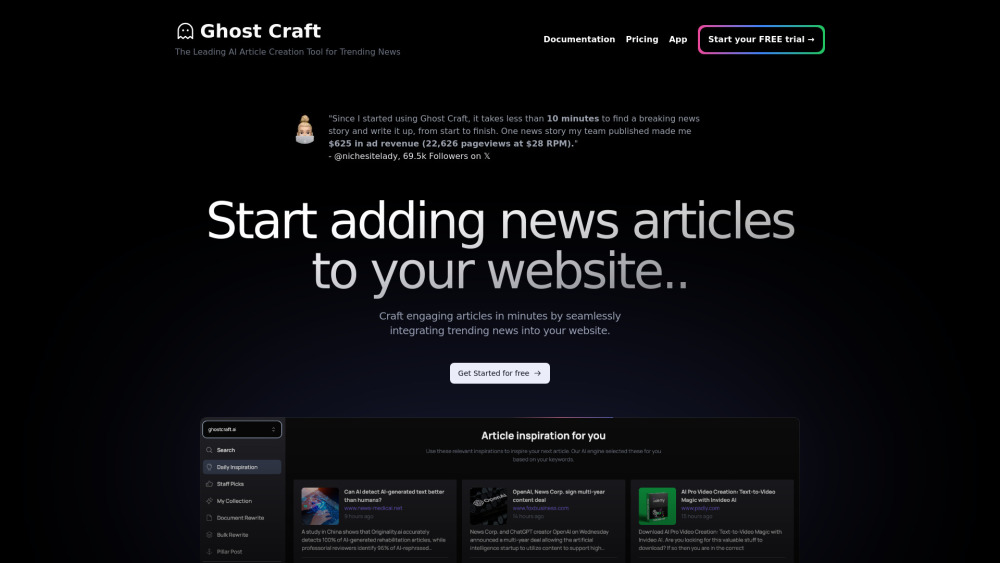
發現一款創新的人工智慧工具,專為快速而引人入勝的新聞文章創作而設計。此技術非常適合新聞工作者、部落客和內容創作者,旨在簡化寫作過程,同時保持質量和讀者的興趣。輕鬆提升您的內容,讓引人注目的新聞講述隨時在您指尖。
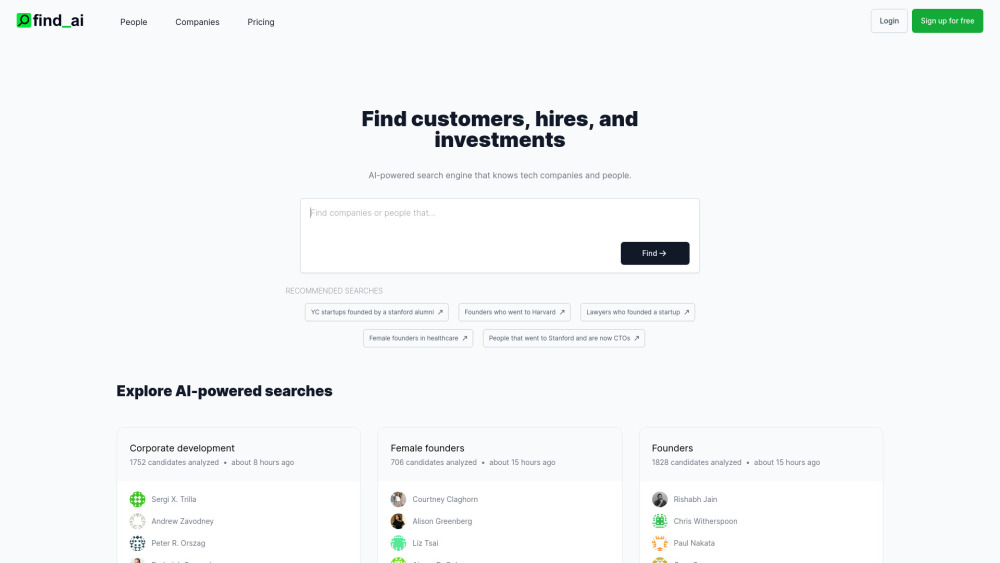
探索一個由人工智慧驅動的搜尋引擎如何改變企業和個人尋找資訊的方式。透過運用先進的演算法,這一創新工具提升了搜尋的準確性和效率,使得連接到關鍵數據、資源和見解變得更容易。體驗未來搜尋的智慧解決方案,專為企業和個人需求量身打造。

Find AI tools in YBX
Related Articles
Refresh Articles