蘋果推出 OpenELM:針對設備性能優化的緊湊型開源 AI 模型
Most people like
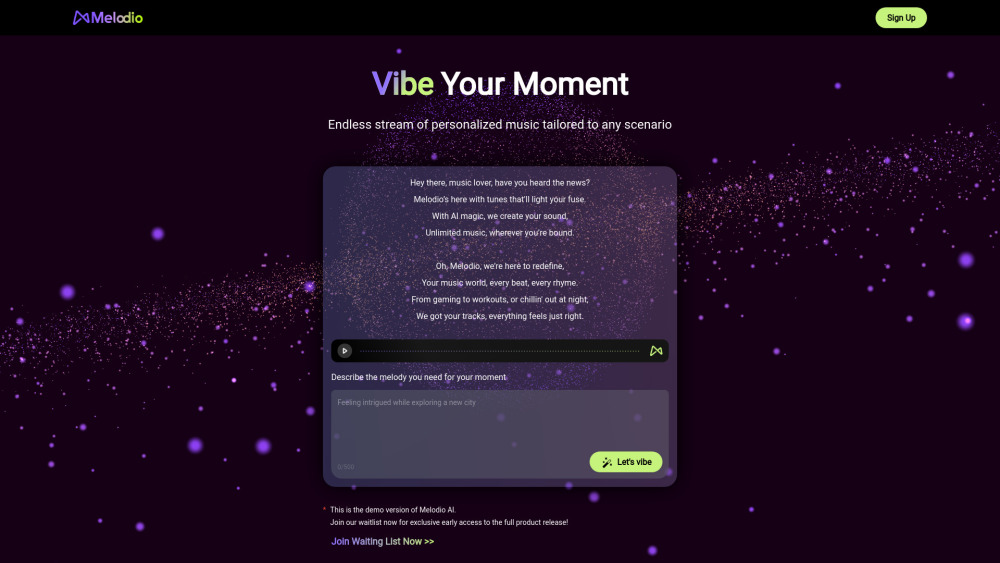
探索專為增強您的聆聽體驗而設計的終極個性化 AI 音樂伴侶。這個創新工具根據您的獨特品味量身定制音樂推薦,為您創造專屬的音樂配樂。藉由先進的算法,它從您的偏好中學習,提供與您的情緒相契合的精選播放列表,確保每一個音符都完美符合您的氛圍。擁抱音樂的未來,讓這位 AI 伴侶伴隨您音樂旅程的發展,使每次聆聽都獨一無二。
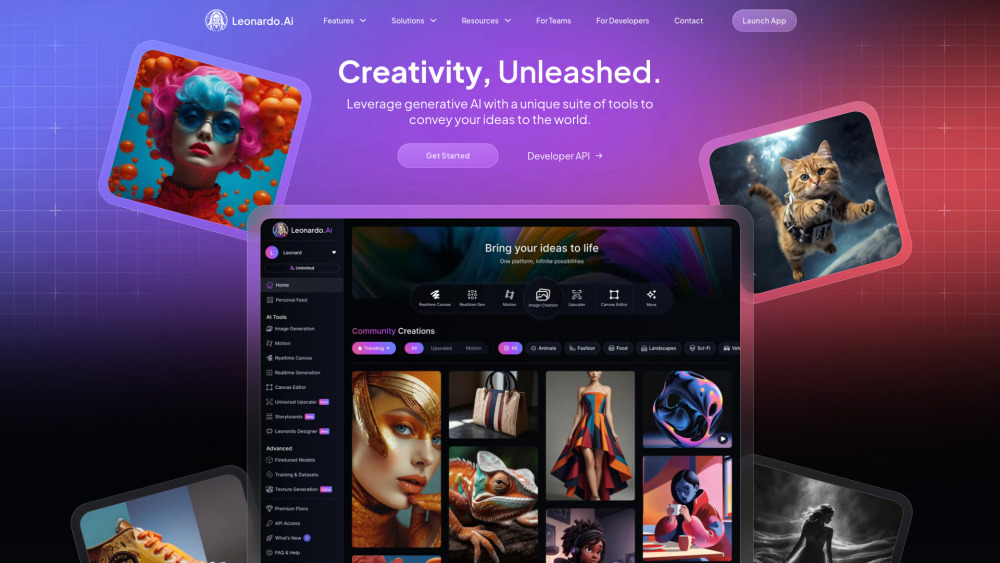
透過利用人工智慧圖像與視頻生成的力量,釋放您創意工作的潛力。這項創新技術使藝術家、行銷專業人士和內容創作者能夠輕鬆製作驚豔的視覺效果和動態影片。探索人工智慧如何提升您的專案,增強您的敘事,並前所未有地吸引您的觀眾。

Find AI tools in YBX
Related Articles

Refresh Articles