Apple 的 ToolSandbox 揭示了明顯的差距:開源 AI 落後於專有模型
Most people like
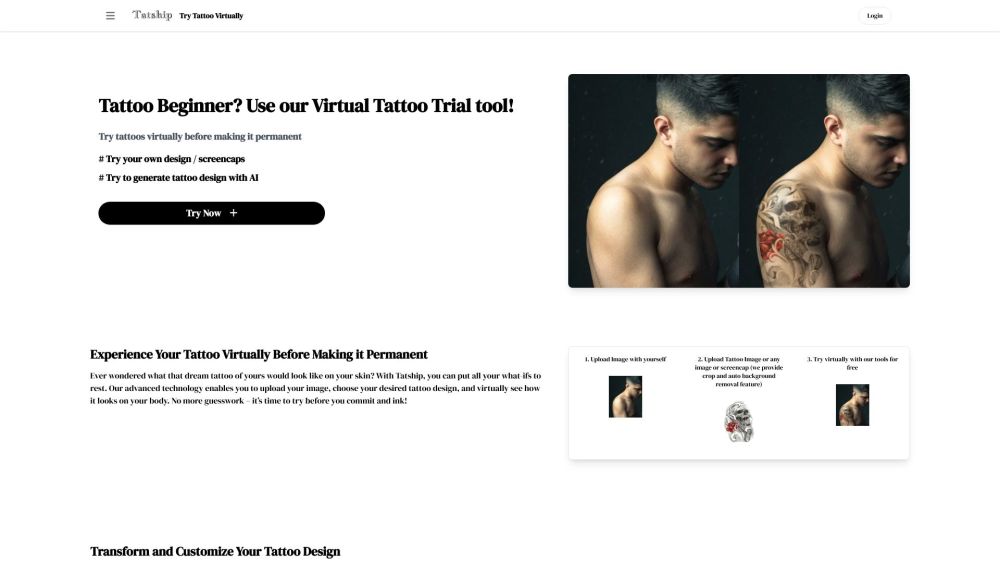
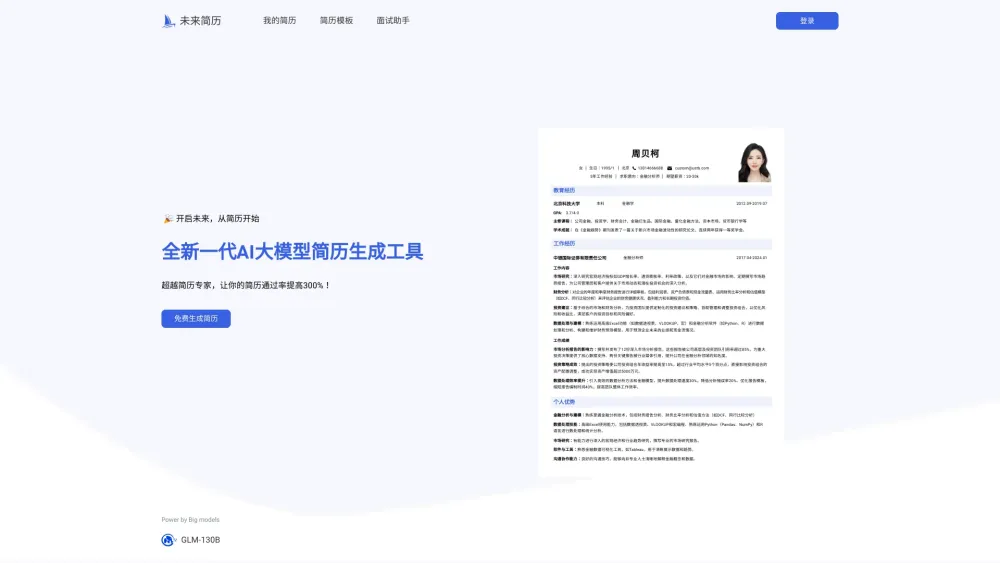
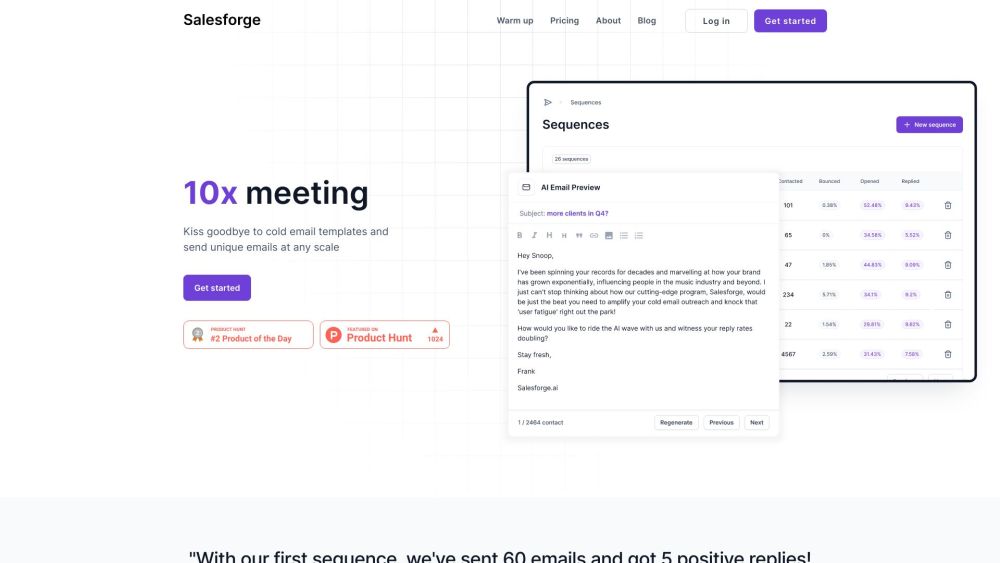
探索我們的AI驅動電子郵件外展平台的強大功能,專為創造獨特且個性化的電子郵件而設計,與您的受眾產生共鳴。提升您的溝通策略,透過量身訂製的信息在擁擠的收件箱中脫穎而出,提高互動率。

介紹我們的 AI 作業幫手,旨在為您提供準確的解答和指導,滿足您所有的學術需求。無論您在面對複雜的數學問題、撰寫論文,或是進行研究,我們的智能工具都能通過提供準確且可靠的答案,提升您的學習體驗。今天就開啟您的學術潛力吧!
Find AI tools in YBX
Related Articles
Refresh Articles