Assembly AI 推出 Universal-1 模型,與 Whisper 相比,幻覺現象減少了 30%
Most people like
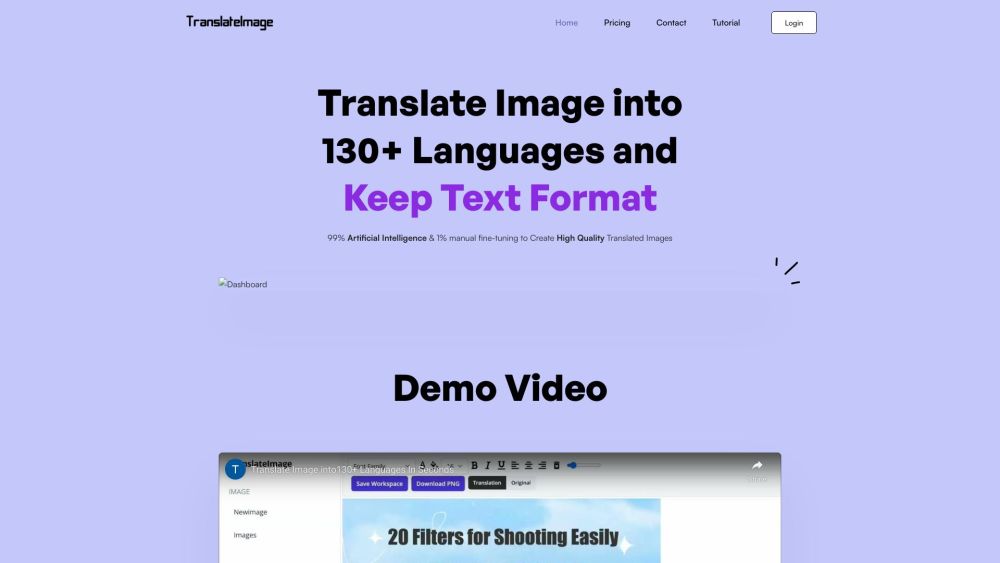
將圖像轉換為多種語言,而不改變其原始文本格式。此過程確保內容的視覺完整性得以維持,同時使其能夠被全球多元化的受眾所理解。探索如何無縫地翻譯圖像,增強跨語言障礙的交流。
介紹我們專為網路和行動應用程式設計的AI原生搜尋API。透過尖端的搜尋功能,提升您的用戶體驗,利用人工智能提供高度相關的結果。 我們的API優化了搜尋效率,確保無縫整合並提升應用程式的互動性。今天就解鎖智能搜尋功能的潛能!


Find AI tools in YBX
Related Articles
Refresh Articles