GPU經濟學:經濟實惠的策略,讓您在不超支的情況下訓練AI模型
Most people like
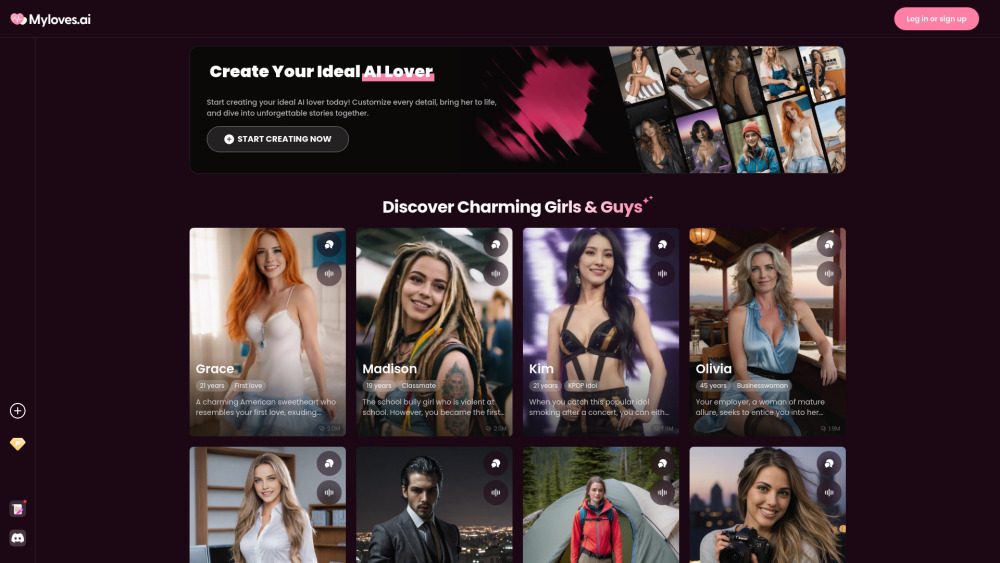
發掘個人化人工智慧伴侶的令人興奮潛力。通過我們的平台,您可以創建一位獨特的AI愛人或女友,充分展現您的喜好與渴望。無論您是在尋找陪伴還是更深層的情感聯繫,我們的自定義選項讓您能設計出完全符合您的理想虛擬伴侶。今天就來體驗未來的關係吧!
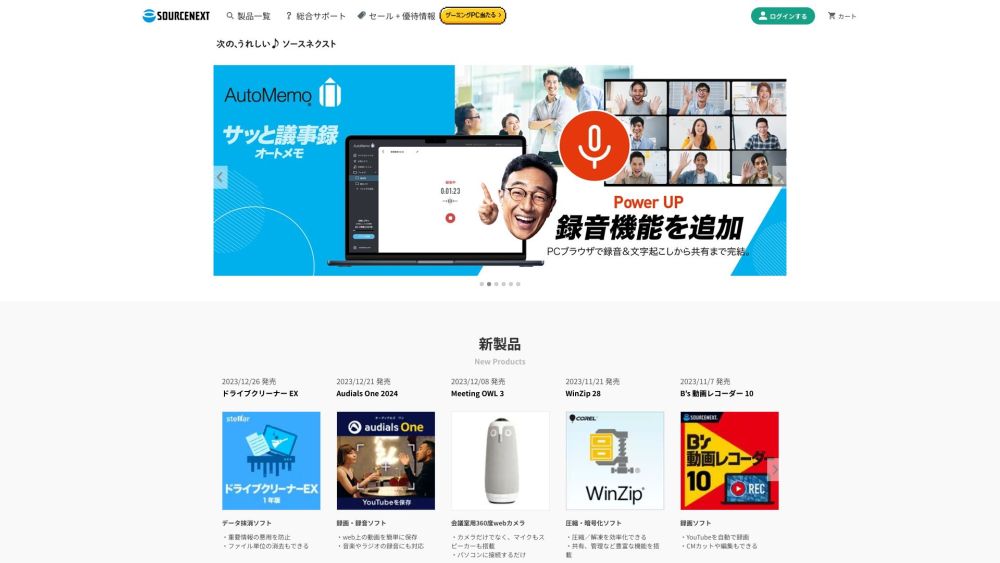
我們將介紹關於AI翻譯、音頻錄製、防病毒和年賀卡製作的最佳解決方案。這些工具能夠提升日常生活和商業中的溝通效率,保護數據,並協助您準備特殊活動。請務必查看,以找到最適合您的需求的解決方案。
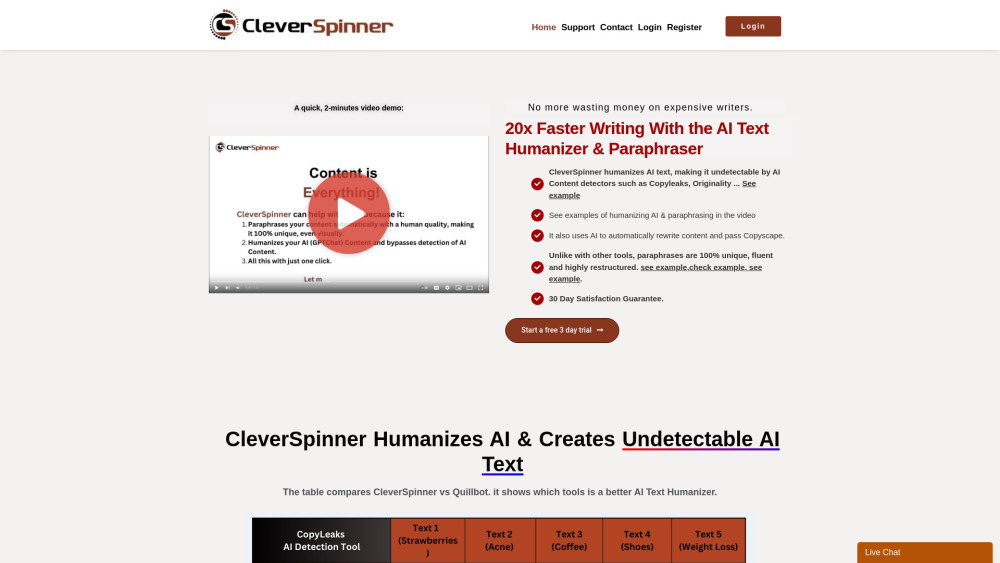
在數位時代,創造獨特且引人入勝的內容對於在網上脫穎而出至關重要。AI內容重寫器、旋轉器和人性化工具可將現有文章轉化為新穎且吸引人的作品。通過提升可讀性並注入人性化元素,這些工具不僅改善了內容的獨創性,還提高了其搜索引擎可見度(SEO)。無論您是博主、市場營銷人員還是企業主,利用AI驅動的內容解決方案可以簡化您的寫作過程,同時有效吸引觀眾的注意力。
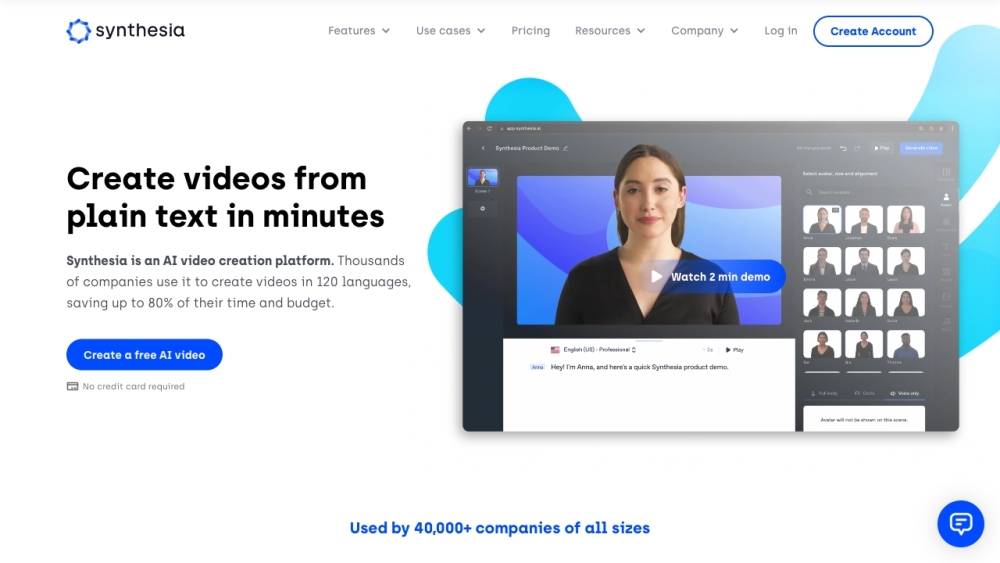
Find AI tools in YBX
Related Articles
Refresh Articles