Nvidia 的 Llama-3.1-Minitron 4B:一款超越預期的強大小型語言模型
Most people like
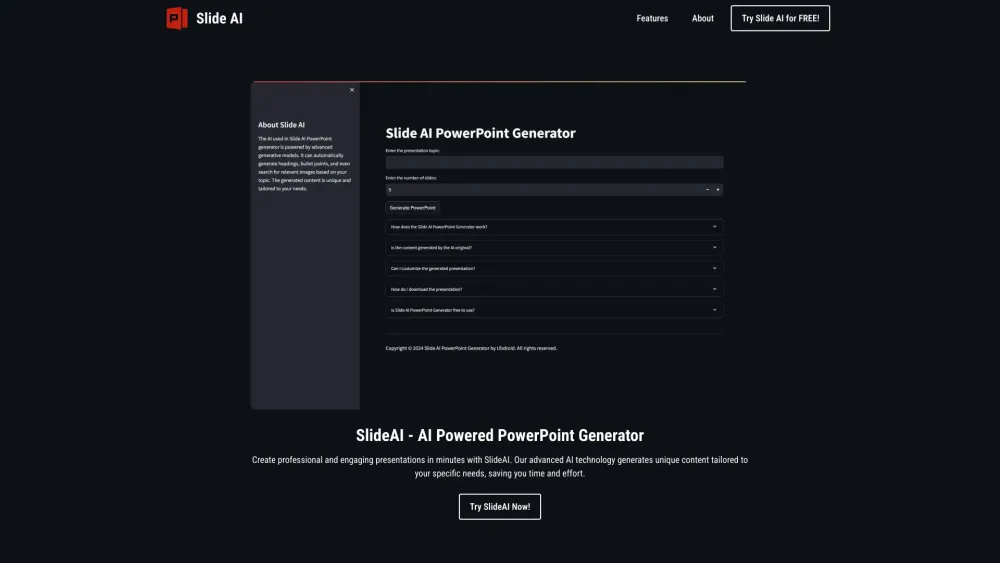
您是否時間緊迫卻需要呈現引人入勝的演示文稿?憑藉我們的創新工具,您可以在幾分鐘內製作出令人驚豔的演示。告別漫長的準備時間,迎接充滿活力的專業幻燈片,吸引觀眾的目光。探索如何輕鬆將您的想法轉化為視覺吸引力強的演示,而不妥協品質。
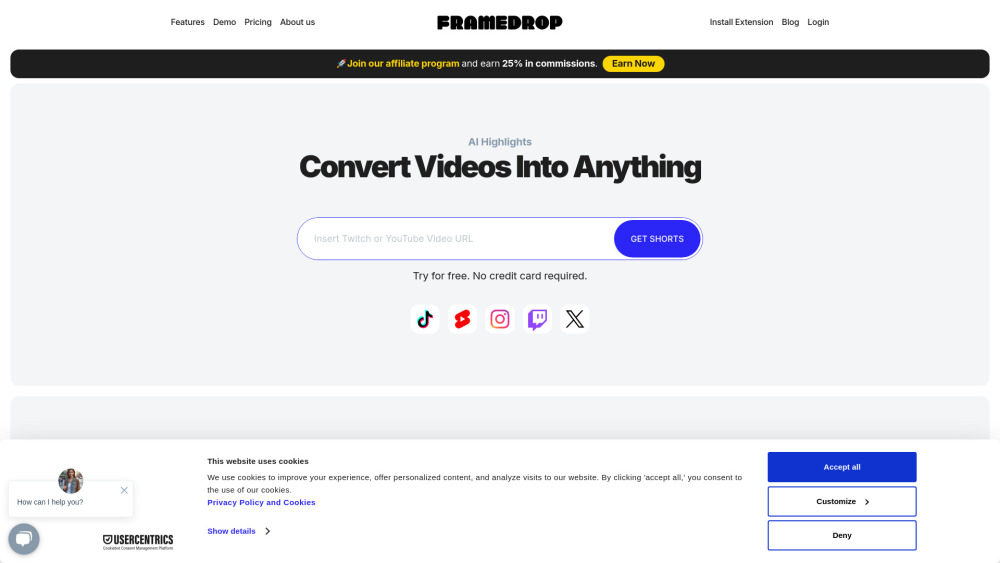
您是否在尋找一款能輕鬆將視頻轉換為引人入勝的短格式內容的AI工具?探索這個創新的解決方案如何提升您的視頻營銷策略,簡化內容創建流程,並有效地吸引您的觀眾。了解使用AI技術將長視頻轉換為簡潔、富有影響力的片段,讓觀眾產生共鳴的優勢。
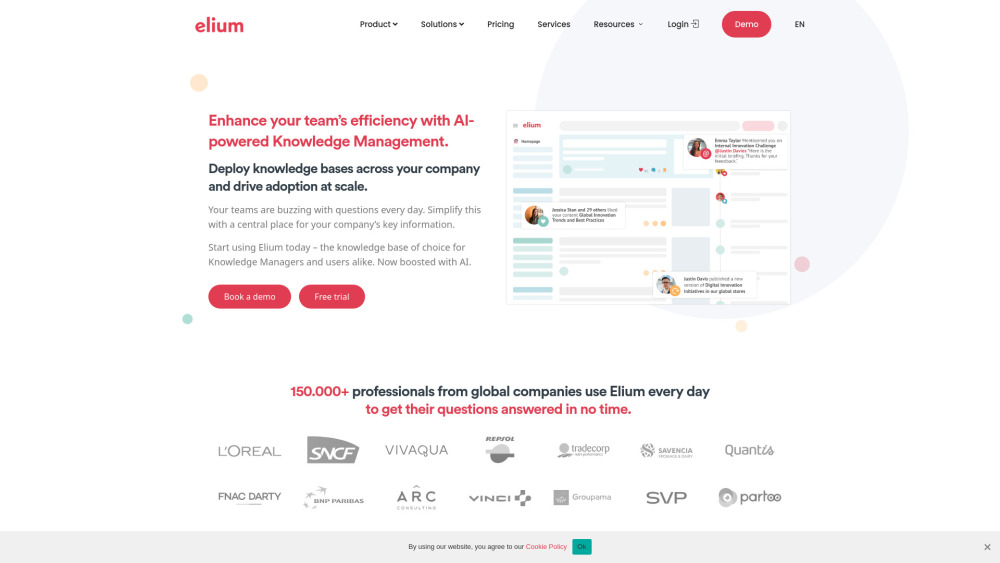
在當今快節奏的數位環境中,知識分享平台在發揮集體智慧方面扮演著至關重要的角色。這些平台提供一個集中空間,使個人和組織能夠交流思想和資源,從而促進合作和創新。這不僅使使用者能夠獲取多元的見解,還驅動了明智的決策和有效的問題解決。讓我們一起探討一個強大的知識分享平台如何提升集體智慧,並改變我們合作學習和工作的方式。
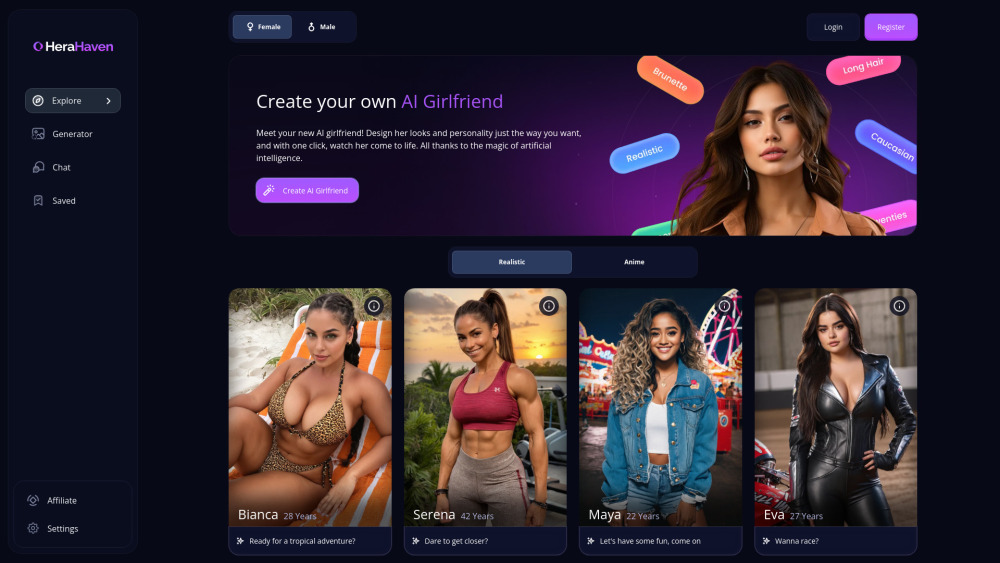
Find AI tools in YBX
Related Articles
Refresh Articles