探索 ImageDream:將照片轉換為驚艷 3D 模型的 AI 模型
Most people like
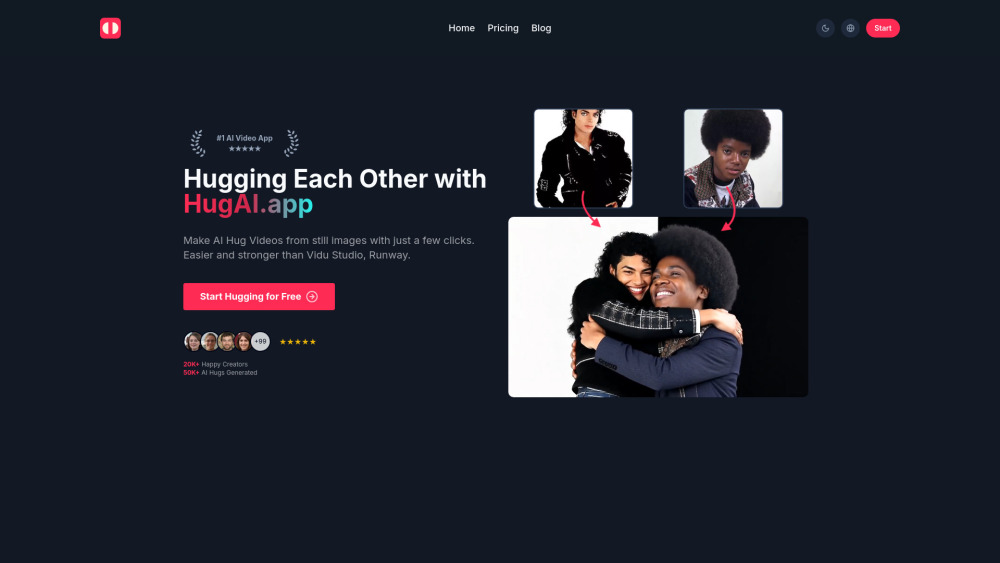
介紹一款創新的人工智慧工具,將您珍貴的照片轉化為溫馨的擁抱影片。這個易於使用的平台讓您的回憶生動活現,透過個性化的視覺敘事方式,讓您以獨特的方式表達愛與支持。輕鬆製作感人的擁抱影片,與摯愛分享喜悅!

在當今快速變化的數位環境中,建立無縫的數據基礎設施對於希望優化運營和促進增長的企業來說至關重要。精心設計的數據系統不僅促進數據流通,還使組織能夠根據即時洞察做出明智決策。透過實施高效的數據基礎設施,公司可以提升協作、精簡流程,最終提高整體生產力。了解如何有效設置您的數據基礎設施,以支持商業目標並確保長期成功。
Find AI tools in YBX
Related Articles
Refresh Articles