谷歌DeepMind推出“超人类”人工智能系统:革新事实核查,降低成本,提高准确性
Most people like
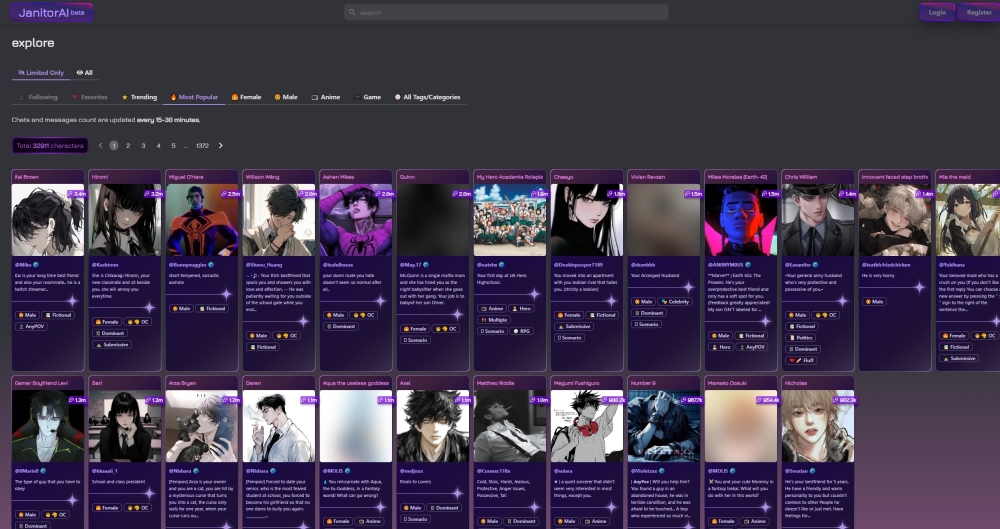
使用Janitor AI设计个性多样的NSFW虚构聊天机器人角色。通过这款工具,您可以轻松打造适合不同需求和兴趣的聊天伙伴。无论是友好的交流还是更刺激的互动,Janitor AI都能帮助您实现创意构想。
全球企业正在越来越多地采用人工智能解决方案,以提升效率和创新能力。这些解决方案不仅能够改变企业的运营方式,还能帮助它们在激烈的市场竞争中脱颖而出。无论是数据分析、客户互动还是流程自动化,人工智能技术正成为企业发展的关键驱动力。获取最新的人工智能发展动态,了解全球企业如何利用这些先进技术,实现转型与增长。

Find AI tools in YBX
Related Articles
Refresh Articles