Cohere推出开放源码LLM:支持101种语言,助力全球AI交流
Most people like
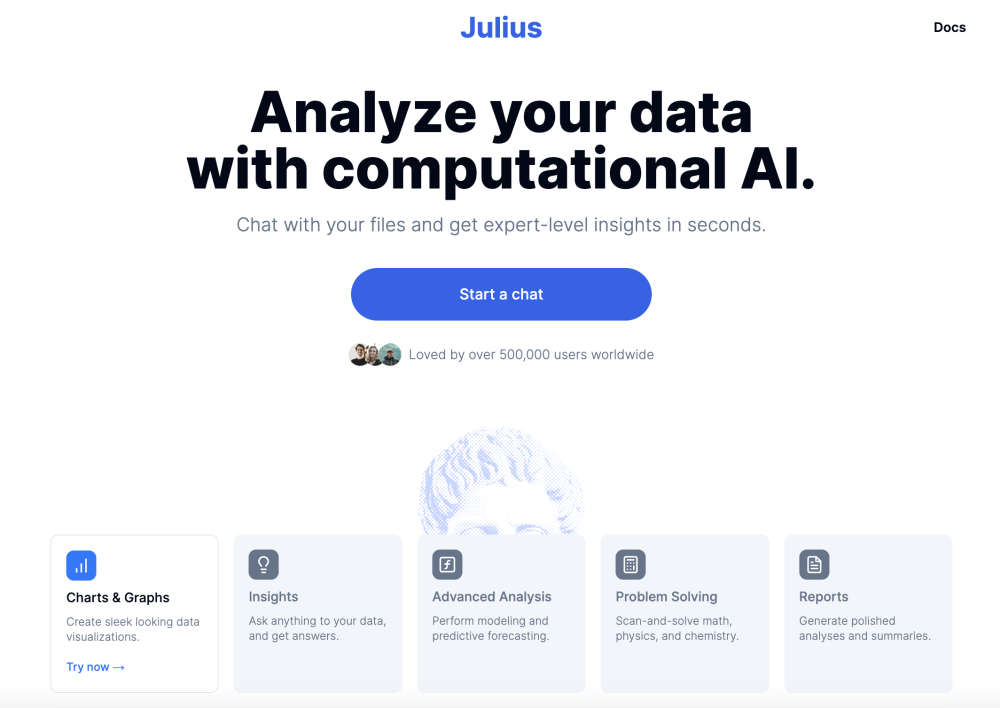
AI数据分析师:提升数据可视化与分析的智能助手
在当今数据驱动的世界中,AI数据分析师成为了企业和个人进行数据可视化和分析的重要工具。通过智能算法和深度学习技术,这些分析师帮助用户更有效地理解和呈现复杂的数据,从而为决策提供支持。无论是在商业、科研还是日常操作中,AI数据分析师都能显著提升数据处理的效率与准确性。
引入公正可信的AI搜索引擎,是为用户提供更准确、可靠的信息来源。这个系统旨在打破传统搜索引擎的局限,确保用户获得的搜索结果不仅快速,而且公正。通过前沿的人工智能技术,我们致力于创建一个透明、可信赖的平台,让用户在信息获取时感受到公平性和安全感。
Find AI tools in YBX
Related Articles
Refresh Articles