Stability AI推出Stability Audio:音效设计专业人士的变革者
Most people like
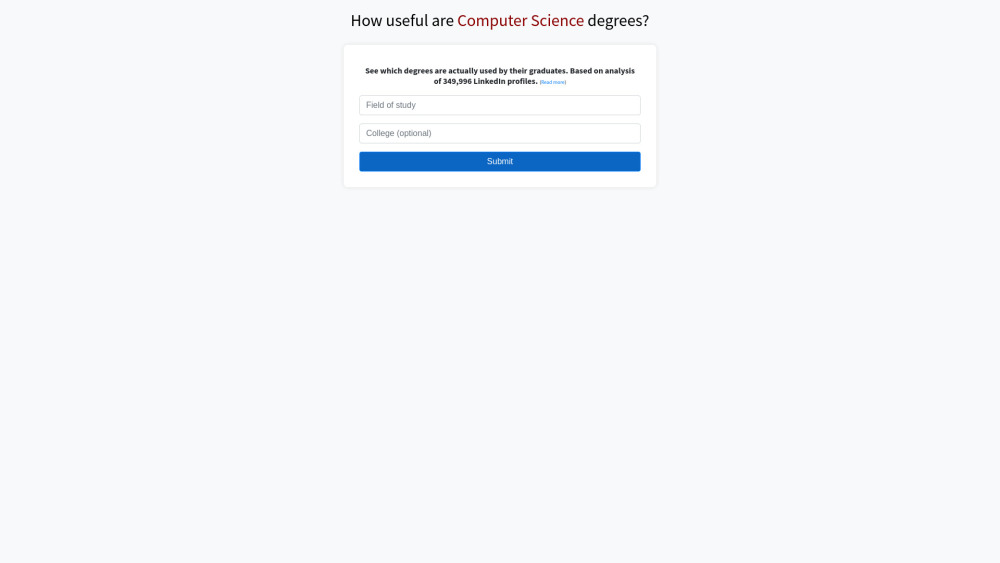
学位与毕业生职业成果的人工智能分析是一个深入探讨教育与职业匹配的重要领域。通过运用先进的人工智能技术,我们能够精准评估不同学位对毕业生职业发展的影响,以及这些影响如何在不断变化的就业市场中显现。这一分析不仅为学生选择学位提供参考,还为教育机构优化课程设置和提高毕业生就业率提供有价值的洞见。
Find AI tools in YBX
Related Articles
Refresh Articles