OpenAI's Newest Model Closes the 'Ignore All Previous Instructions' Loophole for Enhanced Interaction
Most people like
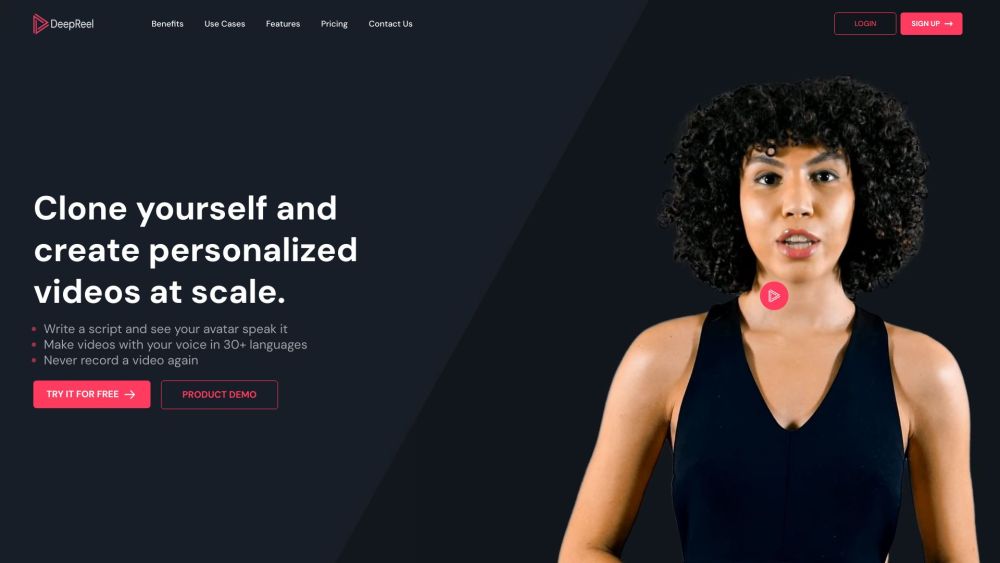
Transform your written content into captivating videos effortlessly with AI technology. Discover how easy it is to convert text into visually stunning presentations that engage your audience, enhance storytelling, and elevate your marketing strategies. Unlock the power of AI-generated videos and revolutionize the way you share your ideas!
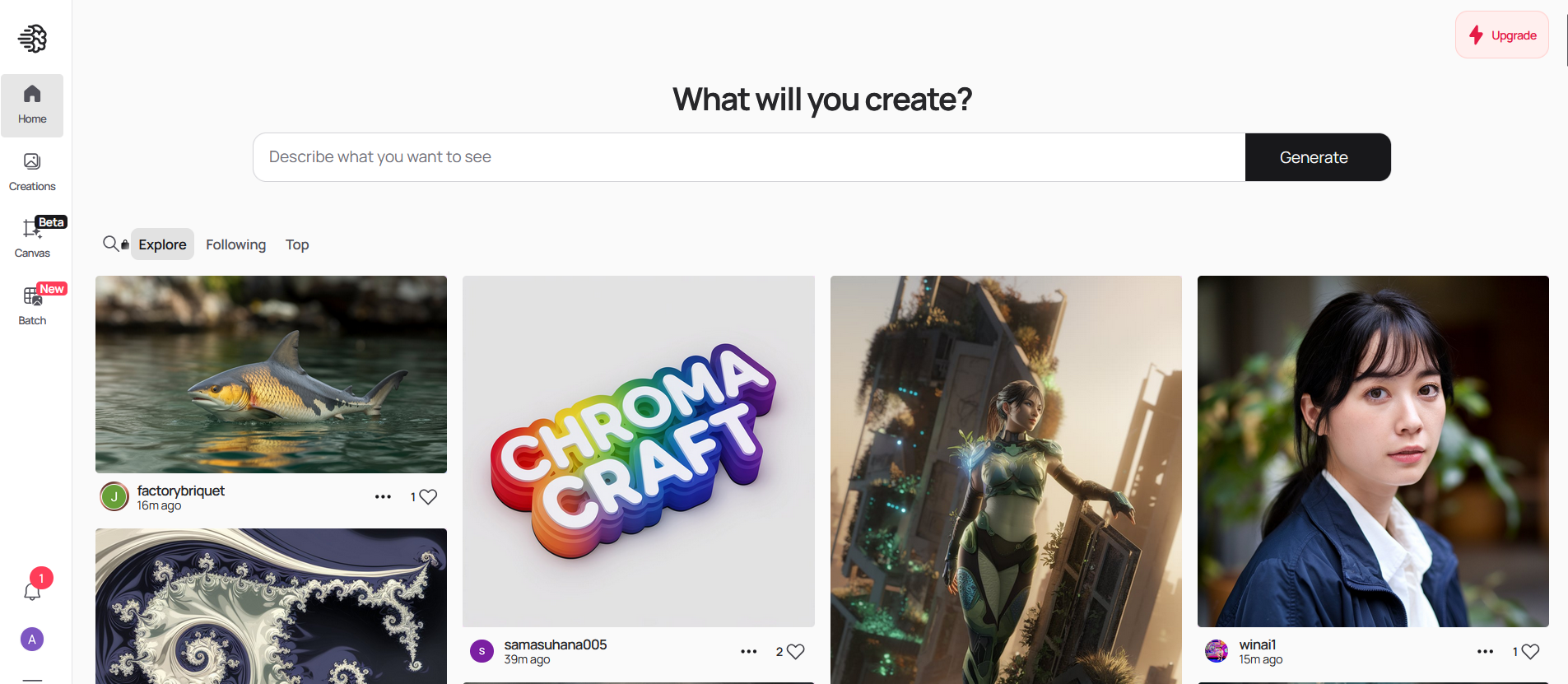
Ideogram is a free-to-use AI tool that generates realistic images, posters, logos and more.

Transform Your URLs with Our AI Video Platform
In today’s digital landscape, the need for seamless content creation and effective URL management is more important than ever. Our innovative AI video platform specializes in transforming URLs, making it easier for users to share and access their favorite videos with just a click. Whether you’re a content creator looking to enhance your online presence or a brand aiming to optimize your video marketing strategy, our platform offers cutting-edge tools to streamline the process and boost engagement. Discover how our AI-powered solutions can elevate your video content and improve your URL transformation efforts today!
Find AI tools in YBX
