The New York Times Urges AI Search Engine Perplexity to Cease Use of Its Content
Most people like

Transform your video content with an AI video generator designed to produce stunning, high-quality videos effortlessly. Whether you're a business seeking to enhance your marketing materials or a content creator aiming to captivate your audience, our advanced AI technology simplifies video production. Discover how you can elevate your storytelling and engage viewers like never before with our innovative video generation tool.
Discover the power of engaging AI conversations and seamless task automation. Unlock the potential of advanced AI to enhance communication while streamlining your workflows for increased productivity.
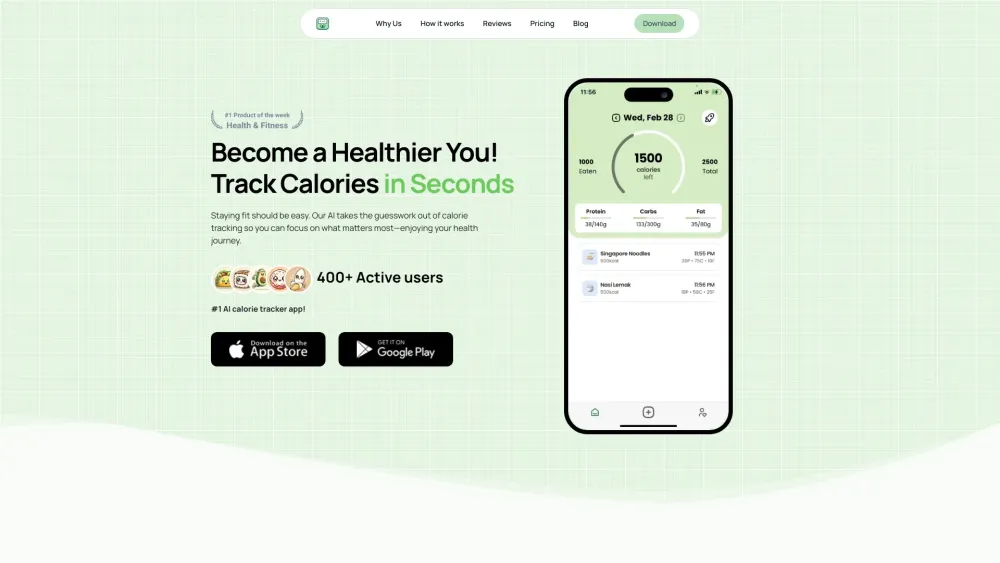
Effortless Calorie Tracking with AI: Simplifying Your Health Journey
Discover the convenience of seamless calorie tracking powered by artificial intelligence. Our innovative approach helps you monitor your dietary intake effortlessly, enabling you to make informed choices for a healthier lifestyle. Embrace this technology to achieve your fitness goals with ease and precision.
Discover Eden AI, where we provide a seamless API that caters to both developers and non-coders, integrating diverse AI technologies for easy access and innovative solutions.
Find AI tools in YBX
Related Articles
Refresh Articles