أعلنت Google DeepMind عن تقديم إطار العمل "Self-Discover" بهدف تعزيز أداء نماذج اللغة الكبيرة (LLMs) وزيادة كفاءة GPT-4.
Most people like
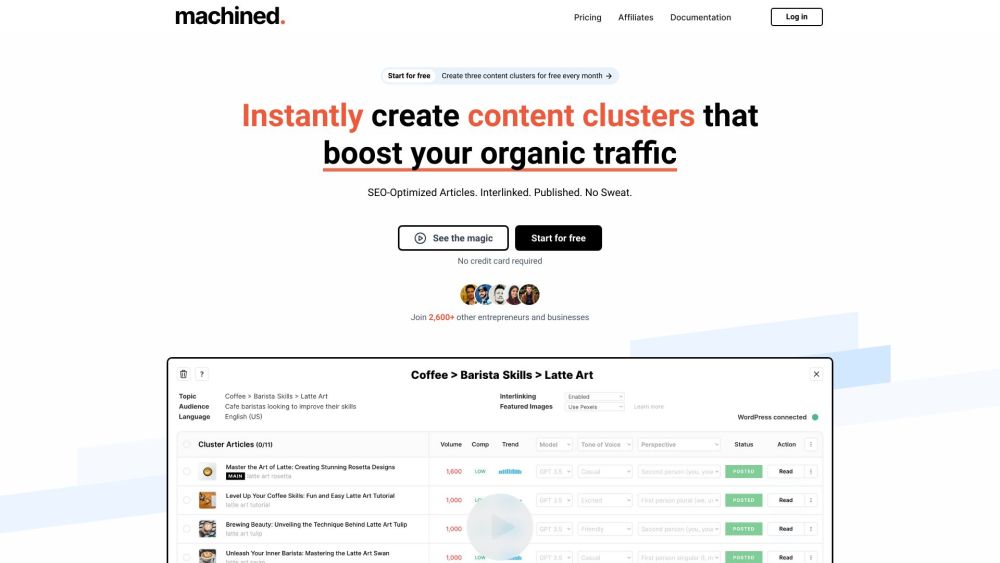
اكتشف منصتنا المدعومة بالذكاء الاصطناعي المصممة لأتمتة تجمعات المحتوى بسهولة. قم بزيادة حركة المرور الطبيعية الخاصة بك وتعزيز تصنيفات البحث باستخدام التكنولوجيا المتقدمة المصممة لتلبية احتياجات التسويق الرقمي الحديث.

في ظل المنافسة الشرسة اليوم، تسعى الشركات دائماً إلى إيجاد حلول مبتكرة لتحسين منتجاتها. يقدم لكم أداة دمج نماذج الذكاء الاصطناعي—منصة متطورة مصممة لدمج الذكاء الاصطناعي بسلاسة في عملية تطوير المنتج. من خلال الاستفادة من قدرات الذكاء الاصطناعي، تعزز هذه الأداة ميزات المنتج، وتحسن الأداء، وتزيد من تفاعل المستخدمين، مما يضع علامتك التجارية في المقدمة. اكتشف كيف يمكن أن يحدث دمج الذكاء الاصطناعي ثورة في عروض منتجاتك ويرفع من مستوى رضا العملاء.
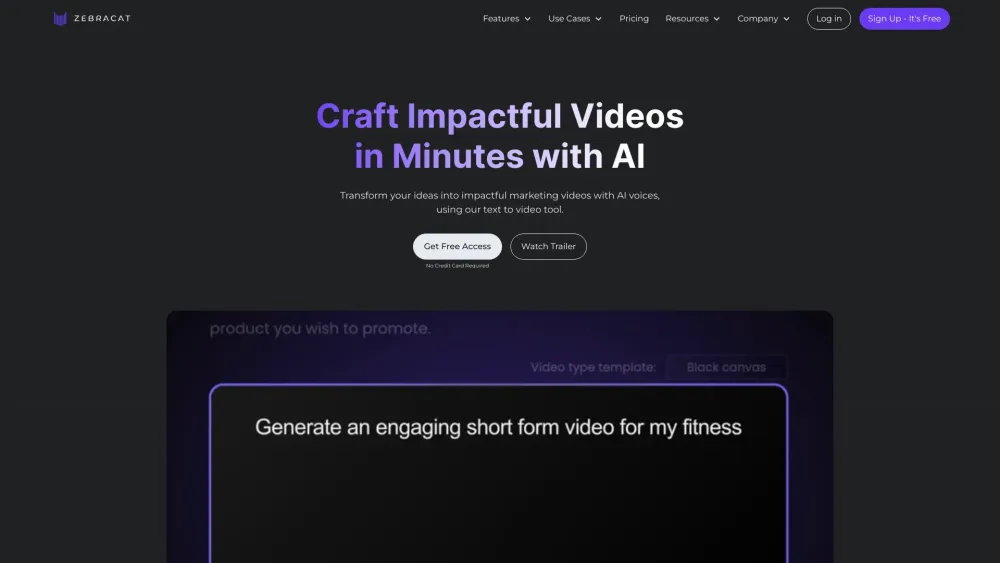
في المشهد الرقمي اليوم، يتطلب التسويق الفعال استخدام مرئيات جذابة تتناغم مع الجمهور. يساهم إنشاء الفيديوهات التسويقية المدعوم بالذكاء الاصطناعي في تسريع عملية إنتاج محتوى عالي الجودة، مما يمكّن العلامات التجارية من جذب المشاهدين بشكل أكثر فاعلية. من خلال الاستفادة من خوارزميات متقدمة وتعلم الآلة، يمكن للشركات الآن إنشاء فيديوهات مخصصة لا تجذب الانتباه فحسب، بل تدفع أيضًا لزيادة التحويلات. استكشف كيف تحول تقنية الذكاء الاصطناعي تسويق الفيديو إلى أداة ديناميكية لنمو العلامة التجارية والتواصل مع الجمهور.
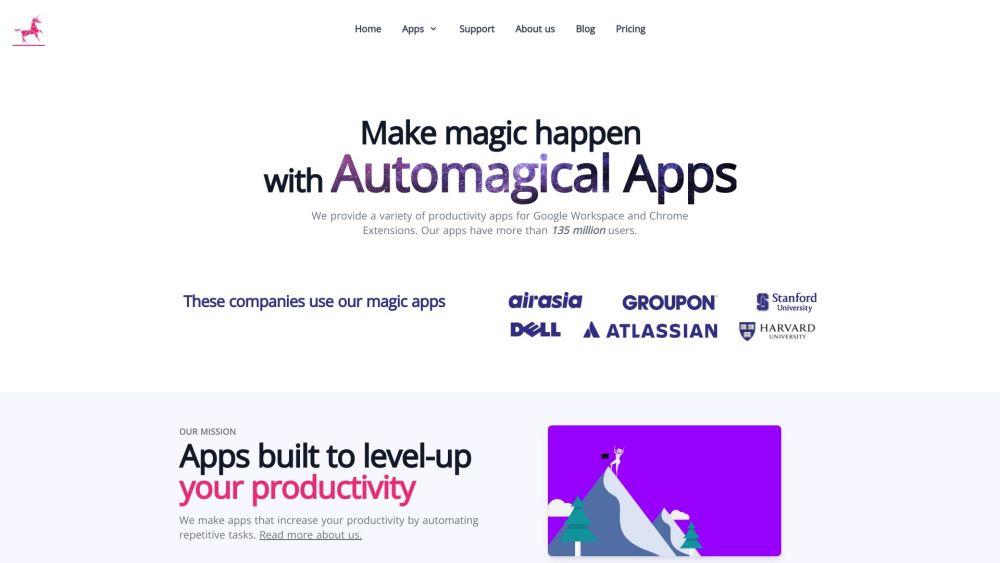
اكتشف أفضل التطبيقات لزيادة الإنتاجية في Google Workspace والإضافات الأساسية لمتصفح Chrome، التي يثق بها أكثر من 3 ملايين مستخدم لتعزيز الكفاءة وتبسيط سير العمل.
Find AI tools in YBX
Related Articles
Refresh Articles