دراسة جديدة من Anthropic تكشف عن وجود 'عملاء نائمين' في أنظمة الذكاء الاصطناعي
Most people like
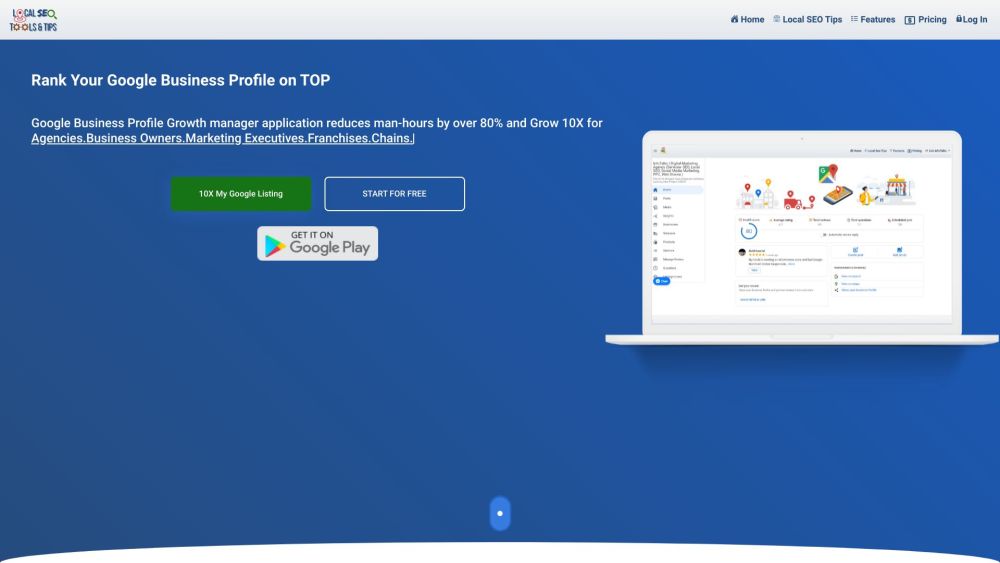
مدير نمو ملفك التجاري على قوقل مصمم لتمكين الشركات من خلال تعزيز تحسين محركات البحث المحلي وتحسين ملفاتها الشخصية على الإنترنت لتحقيق أقصى قدر من الرؤية. من خلال الاستفادة من هذه الأداة القوية، يمكن للشركات تحسين وجودها المحلي بشكل كبير وجذب المزيد من العملاء.

افتح آفاق إبداعك وحوّل أفكارك إلى مرئيات مدهشة باستخدام أدوات الذكاء الاصطناعي. سواء كنت فنانًا أو مصممًا أو هاويًا، فإن استغلال قوة الذكاء الاصطناعي يمكن أن يرفع من مستوى عملية توليد الصور لديك. اكتشف كيفية إنشاء صور جذابة بسهولة واستكشف إمكانيات الأدوات المعتمدة على الذكاء الاصطناعي لتعزيز رؤيتك الفنية. حوّل مفاهيمك إلى واقع اليوم!
فتح الذكاء المكاني الدقيق من خلال الحلول الجغرافية المدعومة بالذكاء الاصطناعي
اكتشف كيف تساهم الحلول الجغرافية المتطورة المدفوعة بالذكاء الاصطناعي في تحويل الذكاء المكاني. من خلال الاستفادة من الخوارزميات المتقدمة وتحليل البيانات، توفر هذه الحلول دقة ورؤى غير مسبوقة، مما يمكّن الصناعات من اتخاذ قرارات مستنيرة استنادًا إلى بيانات جغرافية دقيقة. انغمس في مستقبل التحليل المكاني وعزز فهمك لتعقيدات عالمنا.
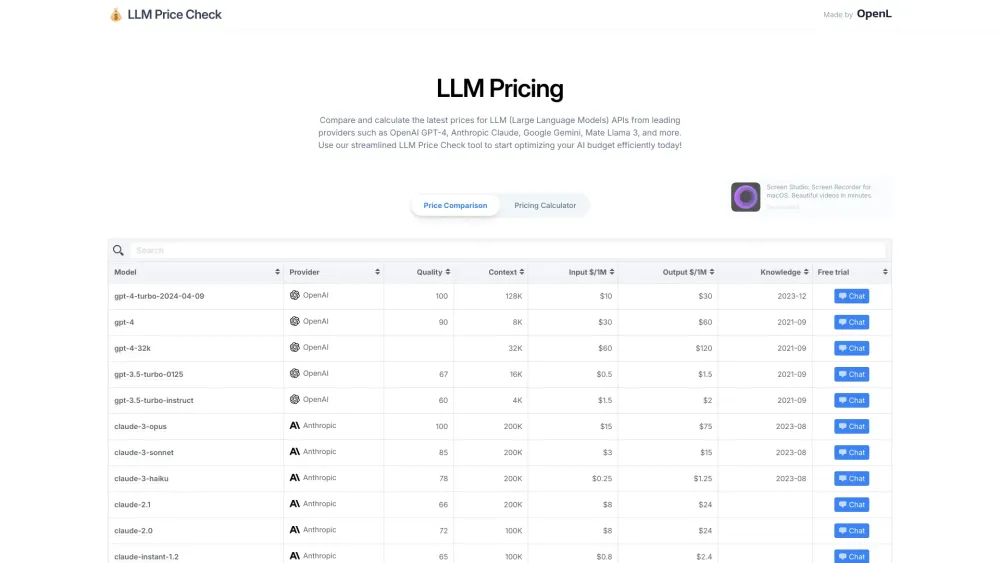
Find AI tools in YBX
Related Articles
Refresh Articles