نموذج Nvidia لاما 3.1 مينيترون 4B: نموذج لغوي صغير قوي يتجاوز التوقعات
Most people like
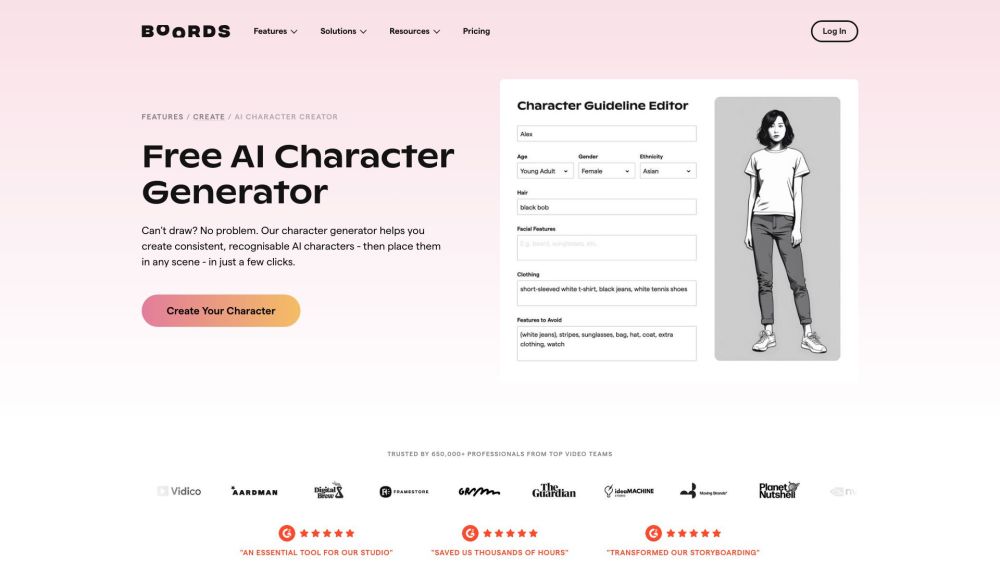
هل تبحث عن إحياء شخصياتك الخيالية بسهولة باستخدام الذكاء الاصطناعي؟ سيوضح لك هذا الدليل كيفية إنشاء شخصيات AI جذابة تثير الانتباه وتحفز الإبداع. اكتشف الأدوات والتقنيات التي تجعل من السهل والممتع والشخصي تصميم الشخصيات لمشاريعك. استعد لإطلاق إمكانياتك الإبداعية مع الذكاء الاصطناعي!
تقديم Voice-Swap: أداة مبتكرة قائمة على الذكاء الاصطناعي مصممة لتحويل الصوت بسلاسة. مثالية للتعاون عن بُعد وتقديم عروض حيوية، تمكّن Voice-Swap المستخدمين من تعزيز مشاريعهم بمرونة صوتية مذهلة.

اكتشف ديكتانوت، تطبيق متنوع للتعرف على الكلام مصمم لتسهيل عملية تسجيل الملاحظات بمختلف اللغات. هذه الأداة المبتكرة تحول الكلمات المنطوقة إلى نصوص، مما يجعلها مثالية للمستخدمين المتعددين اللغات الذين يسعون لتبسيط عملية تسجيل ملاحظاتهم.
في عالم اليوم السريع والمتغير الرقمي، يمكن أن تعزز أتمتة وسائل التواصل الاجتماعي المدعومة بالذكاء الاصطناعي وجودك على الإنترنت بشكل كبير. من خلال الاستفادة من التكنولوجيا المتقدمة، يمكن للشركات تبسيط جدولة المحتوى، وزيادة التفاعل، وتحليل مقاييس الأداء بسهولة. هذه الابتكارات لا توفر الوقت فحسب، بل تتيح لك أيضًا التركيز على صياغة رسائل جذابة تتناغم مع جمهورك. اكتشف كيف يمكن أن تحدث الحلول المدفوعة بالذكاء الاصطناعي ثورة في استراتيجيتك على وسائل التواصل الاجتماعي وتأخذ علامتك التجارية إلى آفاق جديدة.
Find AI tools in YBX
Related Articles
Refresh Articles