Alibabas innovatives KI-System 'EMO' erzeugt realistische sprechende und singende Videos aus Ihren Fotos.
Most people like

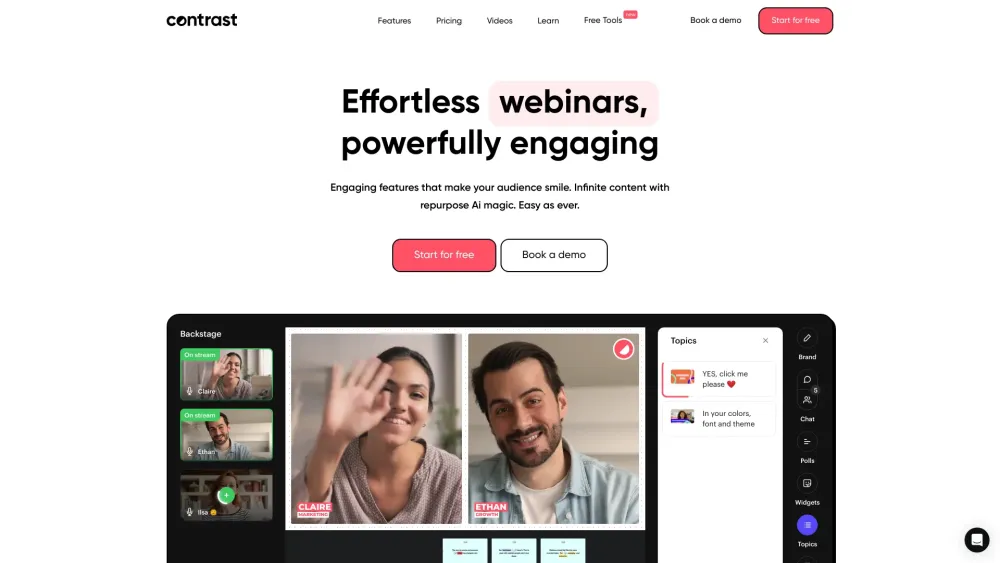
Präsentation des ultimativen KI-Videoeditors zur Erstellung fesselnder Social-Media-Clips
Entfesseln Sie die Kraft unseres fortschrittlichen KI-Videoeditors, der Ihnen hilft, mühelos atemberaubende Videos für soziale Medien zu erstellen. Egal, ob Sie ein erfahrener Creator oder neu im Geschäft sind, dieses intuitive Tool vereinfacht den Bearbeitungsprozess und ermöglicht es Ihnen, ansprechende Inhalte zu produzieren, die Ihr Publikum fesseln und Ihre Online-Präsenz stärken.
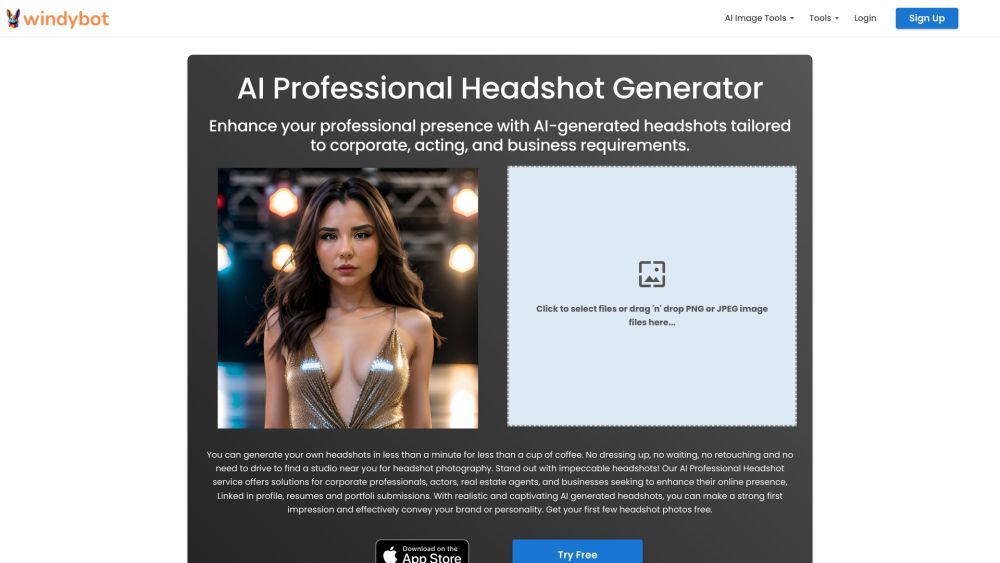
Im heutigen digitalen Umfeld sind auffällige Bilder entscheidend, um Aufmerksamkeit zu erregen und die Botschaft Ihrer Marke zu vermitteln. Mit den Fortschritten in der Technologie sind KI-Tools zur professionellen Bildbearbeitung als leistungsstarke Ressourcen entstanden, um Ihre Fotografie zu verfeinern und zu erhöhen. Diese innovativen Lösungen ermöglichen es den Nutzern, Beleuchtung, Farben und Details mühelos anzupassen und sicherzustellen, dass jedes Bild heraussticht. Ob Sie Fotograf, Marketingexperte oder Content-Ersteller sind, die Nutzung von KI zur Bildverbesserung kann die Qualität Ihrer visuellen Inhalte deutlich steigern und Ihr Publikum effektiver ansprechen.
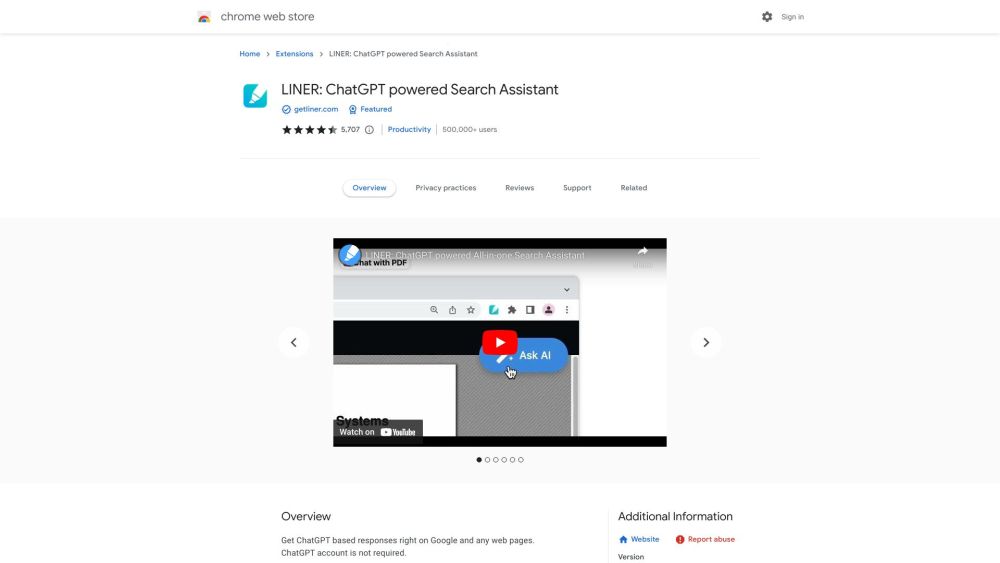
LINER ist ein innovativer, KI-gestützter Arbeitsplatz, der darauf abzielt, den Prozess des Auffindens und Lernens zuverlässiger Informationen effizient zu gestalten. Dank seiner intuitiven Funktionen verbessert LINER Ihr Rechercheerlebnis und ermöglicht es Ihnen, wertvolle Erkenntnisse schneller als je zuvor zu erhalten.
Find AI tools in YBX
Related Articles
Refresh Articles