Entdecken Sie Reliable AI: Das neue Tool von Enkrypt identifiziert die sichersten LLMs für Ihre Bedürfnisse.
Most people like
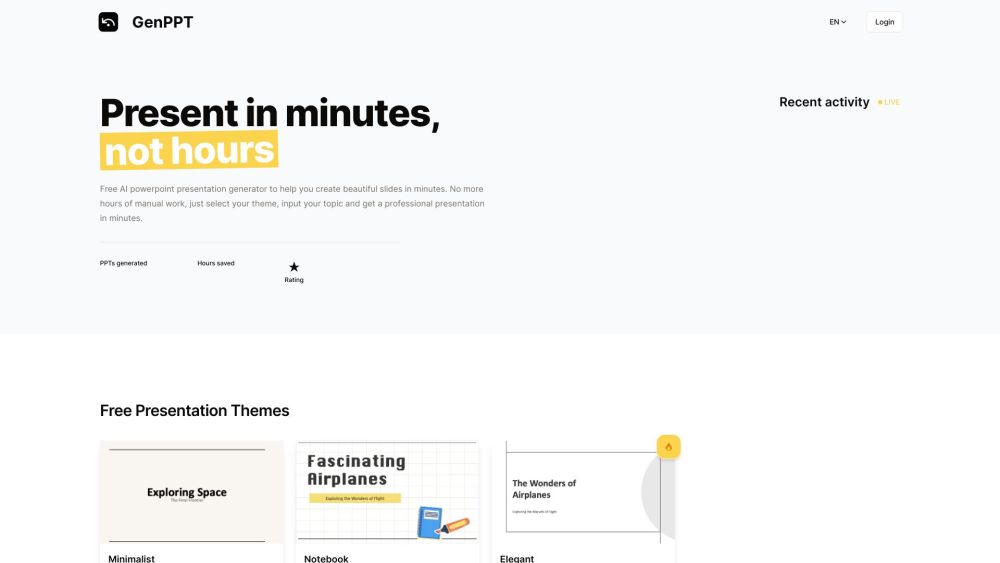
Verwandeln Sie Ihren Präsentationsprozess mit GenPPT – erstellen Sie in kürzester Zeit beeindruckende Folien!
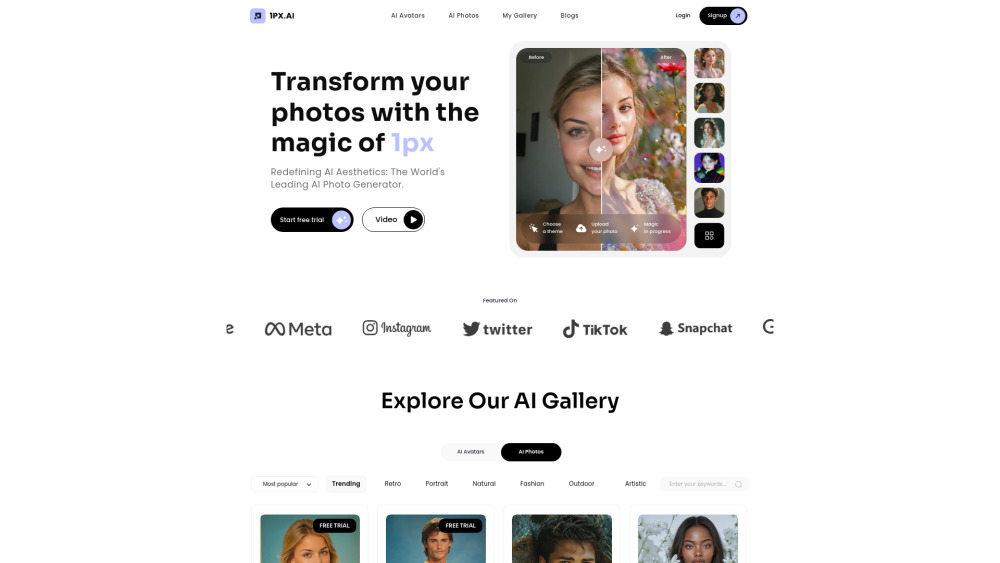
Präsentieren Sie unsere hochmoderne KI-Plattform zur Erstellung von Fotos und Avataren, wo Innovation auf Kreativität trifft! Mit fortschrittlicher Technologie können Benutzer mühelos beeindruckende, personalisierte Bilder und Avatare erstellen. Egal, ob Sie Ihre Online-Präsenz verbessern, einzigartige Grafiken für soziale Medien entwerfen oder einfach Ihr kreatives Potenzial erkunden möchten, unsere Plattform verwandelt Ihre Ideen in wenigen Minuten in hochwertige visuelle Inhalte. Tauchen Sie ein in eine Welt voller Möglichkeiten und entdecken Sie, wie einfach es ist, fesselnde Fotos und Avatare zu generieren, die Ihrem Stil entsprechen!
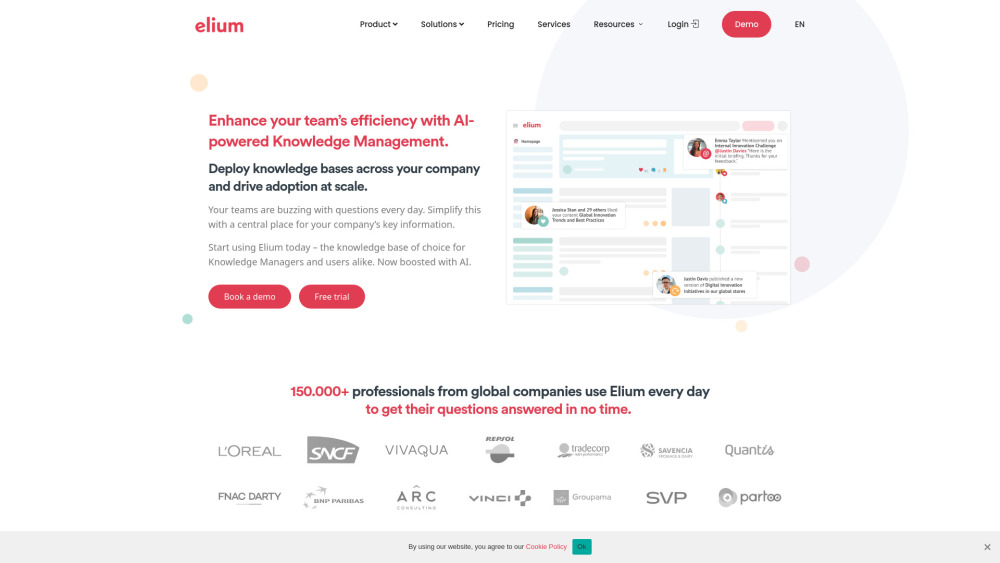
In der heutigen schnelllebigen digitalen Landschaft spielt eine Wissensaustauschplattform eine entscheidende Rolle bei der Nutzung kollektiver Intelligenz. Indem sie einen zentralen Raum bieten, in dem Einzelpersonen und Organisationen Ideen und Ressourcen austauschen können, fördern diese Plattformen Zusammenarbeit und Innovation. Dies ermöglicht es den Nutzern nicht nur, auf vielfältige Erkenntnisse zuzugreifen, sondern fördert auch informierte Entscheidungsfindung und effektive Problemlösung. Begleiten Sie uns, während wir erkunden, wie eine robuste Wissensaustauschplattform die kollektive Intelligenz stärken und die Art und Weise, wie wir gemeinsam lernen und arbeiten, transformieren kann.
Entdecken Sie, wie unsere KI-Lernplattform die Bildung revolutioniert, indem sie anregende, forschungsbasierte Diskussionen fördert und Schreibaufgaben verbessert. Unsere Plattform, die sowohl für Lehrkräfte als auch für Studierende konzipiert ist, nutzt fortschrittliche KI-Technologie, um ein tieferes Verständnis und kritisches Denken zu ermöglichen. Lassen Sie uns gemeinsam eine dynamische Lernumgebung schaffen, in der Forschung zu besseren Schreibfähigkeiten und einem sinnvollen Dialog führt. Erkunden Sie das Potenzial KI-gestützter Einblicke, um die Art und Weise, wie Wissen geteilt und entwickelt wird, zu transformieren.
Find AI tools in YBX
Related Articles
Refresh Articles