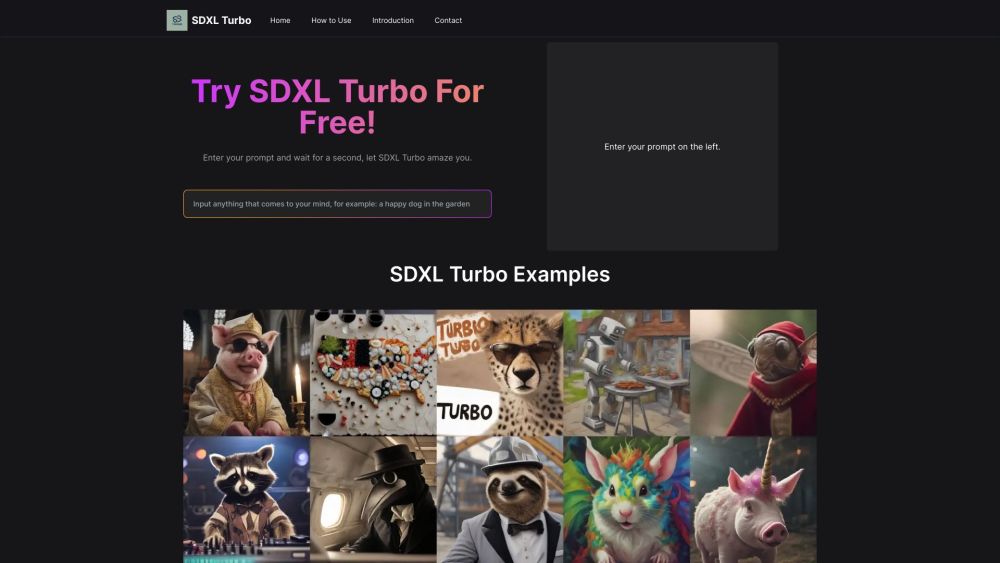
Stability AI hat eine erste Vorschau auf sein neuestes Text-zu-Bild-Generierungsmodell, Stable Diffusion 3.0, veröffentlicht. Dieses Update folgt auf ein Jahr kontinuierlicher Verbesserungen und zeigt eine steigende Raffinesse und Qualität in der Bildgenerierung. Das vorige SDXL-Update im Juli hat das Basismodell erheblich aufgewertet, und nun strebt das Unternehmen noch größere Fortschritte an.
Stable Diffusion 3.0 legt den Fokus auf verbesserte Bildqualität und Leistung, insbesondere bei der Generierung von Bildern aus Multi-Subject-Aufforderungen. Ein bemerkenswerter Fortschritt betrifft die Typografie, die eine frühere Schwäche adressiert, indem sie genaue und konsistente Schreibweisen in den generierten Bildern liefert. Diese Verbesserungen sind entscheidend, da Wettbewerber wie DALL-E 3, Ideogram und Midjourney in ihren aktuellen Updates ebenfalls Wert auf diese Funktion legen. Stability AI bietet Stable Diffusion 3.0 in verschiedenen Modellgrößen an, von 800M bis 8B Parametern.
Dieses Update stellt einen bedeutenden Wandel dar—es ist nicht nur eine Verbesserung vorheriger Modelle, sondern eine vollständige Neugestaltung basierend auf einer neuen Architektur. „Stable Diffusion 3 ist ein Diffusions-Transformer, eine neue Architektur ähnlich der, die im neuesten Sora-Modell von OpenAI verwendet wird“, erklärte Emad Mostaque, CEO von Stability AI. „Es ist der wahre Nachfolger des ursprünglichen Stable Diffusion.“
Der Übergang zu Diffusions-Transformern und Flow Matching läutet eine neue Ära in der Bildgenerierung ein. Stability AI hat mit verschiedenen Techniken experimentiert und kürzlich Stable Cascade präsentiert, das die Würstchen-Architektur zur Leistungs- und Genauigkeitssteigerung nutzt. Im Gegensatz dazu verwendet Stable Diffusion 3.0 Diffusions-Transformer, was einen bedeutenden Wandel im Vergleich zum Vorgängermodell darstellt.
Mostaque erklärte weiter: „Stable Diffusion hatte zuvor keinen Transformer.“ Diese Architektur, die für viele Fortschritte im Bereich generativer KI grundlegend ist, wurde hauptsächlich für Textmodelle reserviert, während Diffusionsmodelle die Bildgenerierung dominierten. Die Einführung von Diffusions-Transformern (DiTs) optimiert den Einsatz von Rechenressourcen und verbessert die Leistung, indem die traditionelle U-Net-Architektur durch Transformer ersetzt wird, die auf latenten Bildbereichen agieren.
Darüber hinaus profitiert Stable Diffusion 3.0 von Flow Matching, einem neuartigen Trainingsansatz für Continuous Normalizing Flows (CNFs), der komplexe Datenverteilungen effektiv modelliert. Forscher weisen darauf hin, dass die Anwendung von Conditional Flow Matching (CFM) mit optimalen Transportwegen zu schnelleren Trainingszeiten, effizienteren Samplergebnissen und verbesserten Leistungen im Vergleich zu konventionellen Diffusionsmethoden führt.
Das Modell zeigt deutliche Fortschritte in der Typografie, was kohärentere Erzählungen und stilistische Entscheidungen in den generierten Bildern ermöglicht. „Diese Verbesserung ist sowohl der Transformer-Architektur als auch zusätzlichen Text-Encodern zu verdanken“, bemerkte Mostaque. „Vollständige Sätze sind jetzt möglich, ebenso ein kohärenter Stil.“
Während Stable Diffusion 3.0 zunächst als Text-zu-Bild-KI vorgestellt wird, bildet es die Grundlage für zukünftige Innovationen. Stability AI plant, in den kommenden Monaten in die 3D- und Video-Generierungsfunktionen zu expandieren. „Wir schaffen offene Modelle, die für unterschiedliche Bedürfnisse genutzt und angepasst werden können“, schloss Mostaque. „Diese Modellreihe in verschiedenen Größen wird die Entwicklung unserer nächsten Generation visueller Lösungen, einschließlich Video, 3D und mehr, unterstützen.“