AI2がオープンソースOLMoモデルを多様なデータセットと二段階カリキュラムで強化し、パフォーマンスを向上させる
Most people like
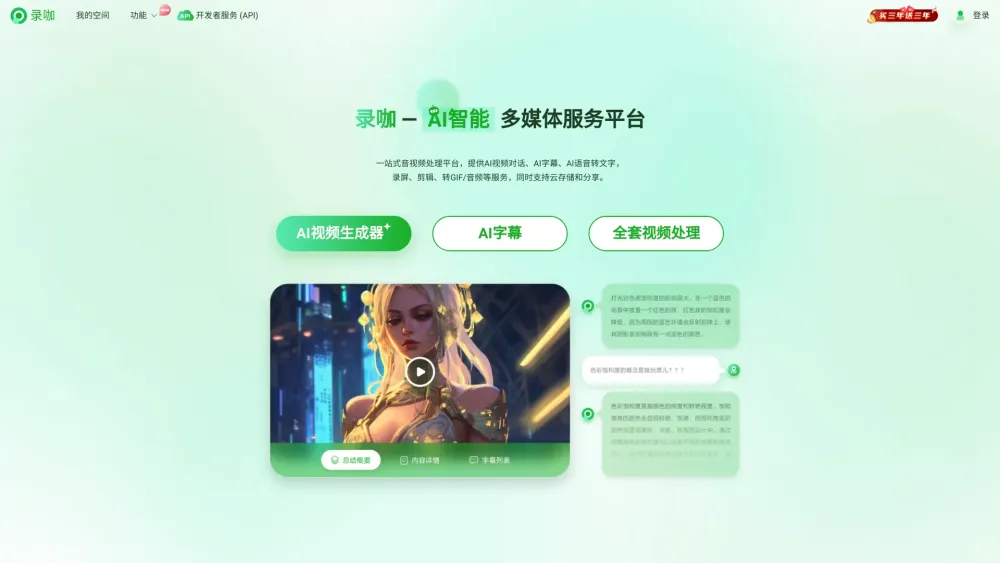
AI駆動の音声・映像処理プラットフォーム:コンテンツ制作と編集の効率と精度を向上
人工知能技術の急速な発展に伴い、音声・映像処理プラットフォームはコンテンツ制作の分野を未だかつてない方法で変革しています。AI駆動のツールは編集の自動化、画質の向上、音声品質の最適化を実現し、クリエイターの作業効率を大幅に向上させます。ソーシャルメディア、ビデオ制作、ライブ配信のいずれにおいても、これらのプラットフォームはユーザーにスマートなソリューションを提供し、コンテンツ制作をより簡単かつ効率的にします。AI駆動の音声・映像処理プラットフォームを探求し、創作体験を全面的に向上させましょう。
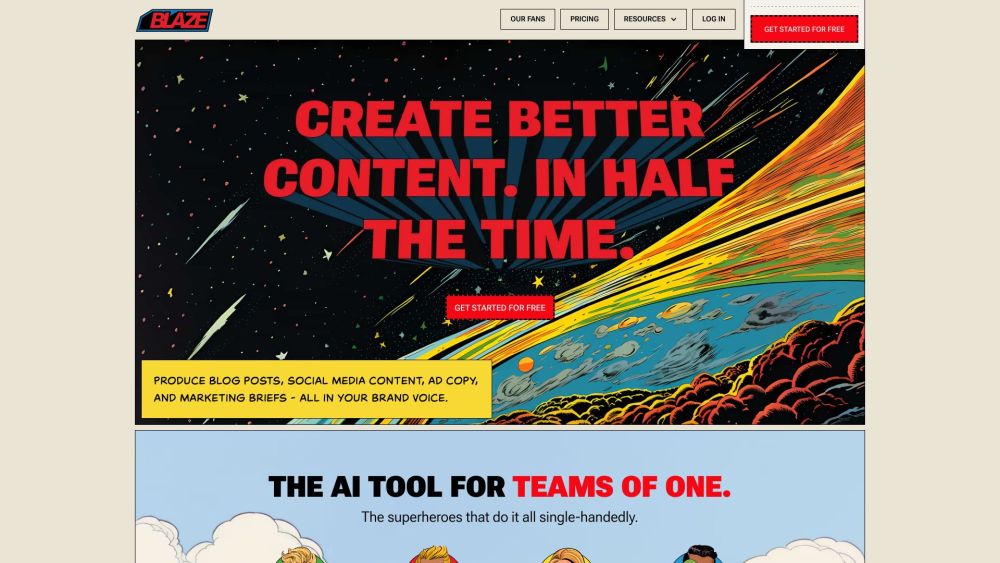
ブランドの声を完璧に捉えるコンテンツを制作するために設計されたAI駆動のツールをご紹介します。オーディエンスとのエンゲージメントを目指す方やブランドアイデンティティを強化したい方に最適です。この革新的なソリューションは、あなたのアイデアをターゲット市場に響く魅力的なストーリーへと変貌させます。あなたのニーズに特化した最先端の技術で、今日からコンテンツ戦略を向上させましょう。
YouTube向けAI脚本作成ツールのご紹介:コンテンツ制作プロセスを革新しよう!
魅力的な脚本でYouTube動画を向上させたいですか?私たちのAI脚本作成ツールは、あなたのようなクリエイターのために特別に設計されています。高度なアルゴリズムと言語処理機能を活用し、魅力的なコンテンツを迅速かつ簡単に生成します。作家のブロックにさようならを告げ、創造的な自由にこんにちは!チュートリアル、ブログ、または教育コンテンツを制作する際も、私たちのツールはあなたの脚本を魅力的にし、オーディエンスに合わせてカスタマイズします。動画制作を向上させ、視聴者をかつてないほど魅了しましょう!
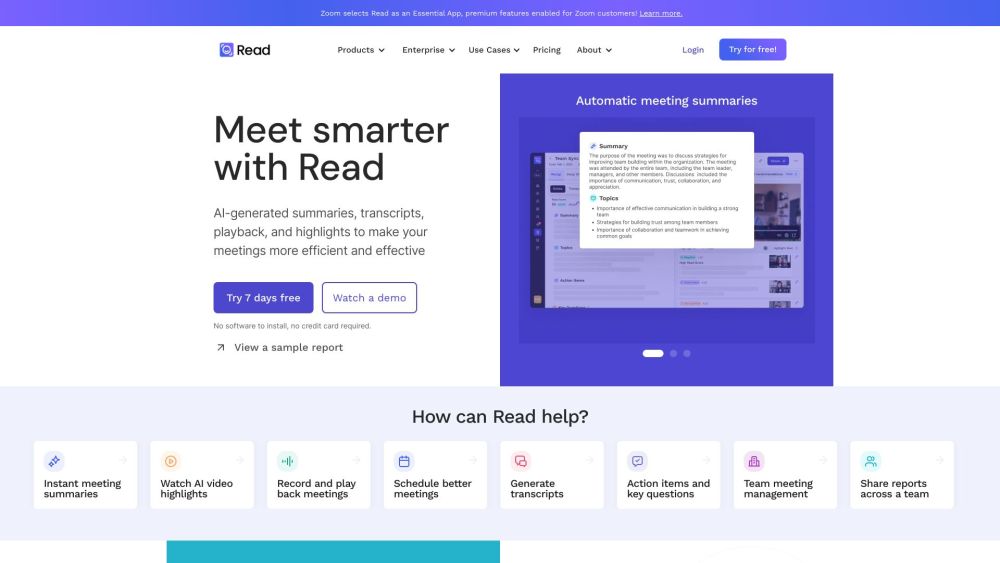
リードを紹介します:スマートスケジューリング、詳細な分析、簡潔な要約、カスタマイズされた提案を通じて会議の健康を向上させるあなたのパートナーです!生産性とウェルビーイングを最優先する、革新的な会議のアプローチを体験してください。
Find AI tools in YBX
Related Articles
Refresh Articles