本物の洞察を解き放つ:Google CloudのAI神話を超えた重要な教訓
Most people like
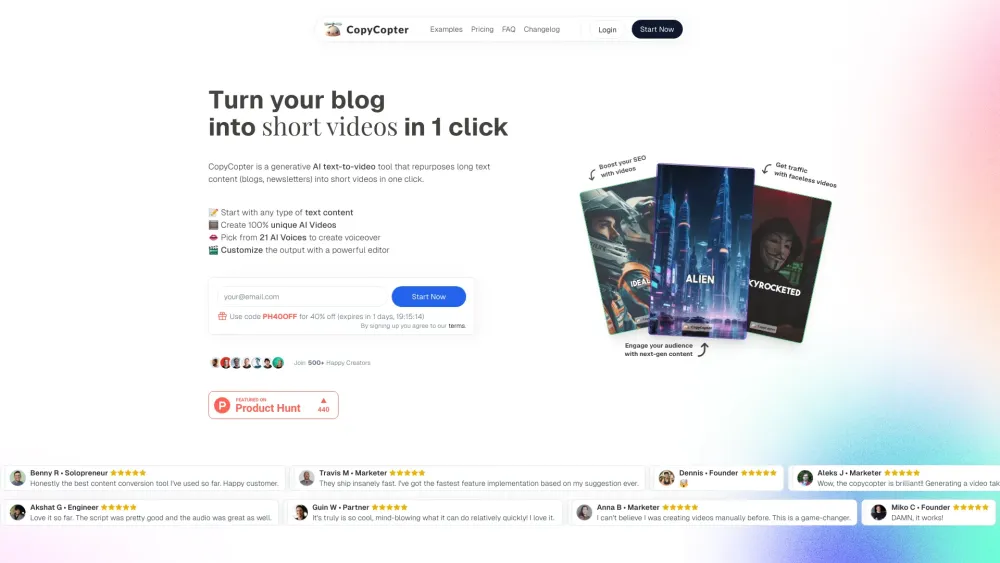
今日のデジタル環境において、文章コンテンツを魅力的な動画に変換することが注目を集める鍵です。テキストを魅力的なビジュアルストーリーテリングに変えることで、より広範なオーディエンスにリーチし、ブランドの視認性を高めることができます。本ガイドでは、テキストからバイラル動画を簡単に生成するための効果的な戦略とツールを探ります。これにより、オンラインでの存在感を最大化し、視聴者をこれまでにない方法で引きつけることができます。それでは、始めてあなたの言葉の可能性を引き出しましょう!
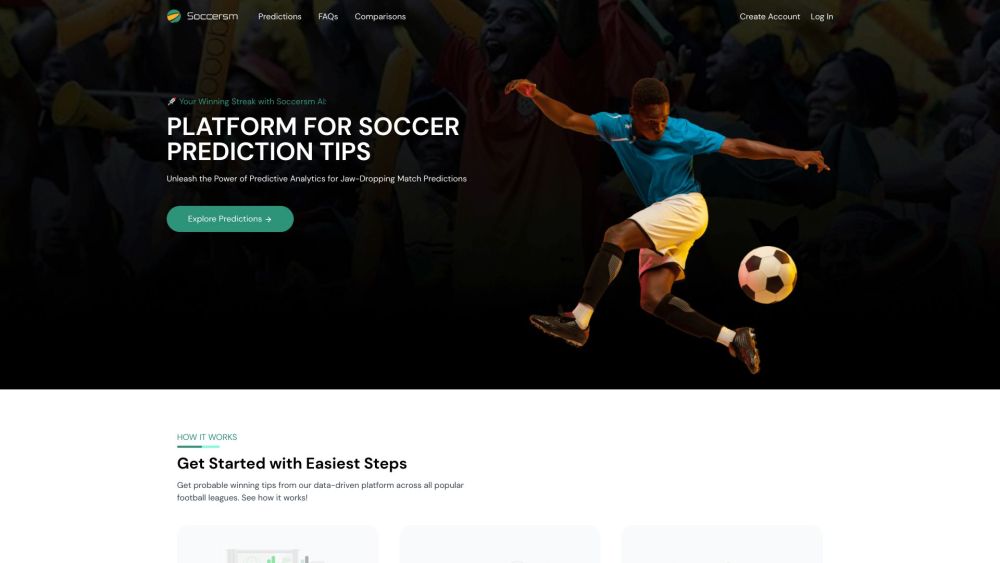
精密な試合前予測と深層分析のために設計された高度なAIツールを紹介します。この革新的な技術はデータ駆動の洞察を活用し、ゲームへの理解を深め、競争において一歩先を行くことを可能にします。
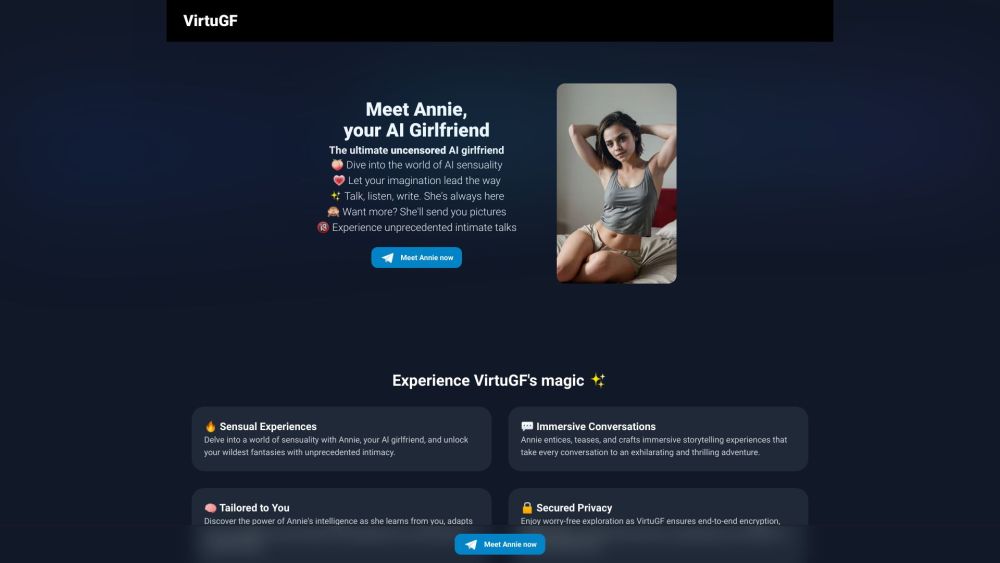
あなたの感情的なニーズと友情を満たすために設計された、検閲のない親密なAIガールフレンドを発見してください。あなたのために特別に調整されたパーソナライズされた対話を提供する先進技術で、つながりと革新のユニークな融合を体験しましょう。未来の関係を受け入れ、かつてないほどの友情を見つけてください。
Find AI tools in YBX
Related Articles
Refresh Articles