言語モデルの速度を300倍に向上させる革新的技術
Most people like
魅力的なAIエンターテインメントの世界を発見しましょう!没入感のあるストーリーテリングからインタラクティブな体験まで、人工知能は遊び方と楽しみ方を再構築しています。最先端の技術を駆使したAI脳エンターテインメントは、楽しさと創造性の無限の可能性を提供します。私たちと一緒に、AIが観客を惹きつけ、エンターテインメントを変革する革新的な方法を探求しましょう。
私たちのAI学習プラットフォームが教育をどのように革新するかをご覧ください。参加型の探求を促進し、作文課題を向上させます。教育者と学生の双方に向けて設計されたこのプラットフォームは、先進的なAI技術を活用し、より深い理解と批判的思考を促進します。探求がより良い作文能力と意義ある対話につながるダイナミックな学習環境の創造に参加しましょう。AI駆動の洞察が知識の共有と発展の方法を変革する可能性を探求してください。
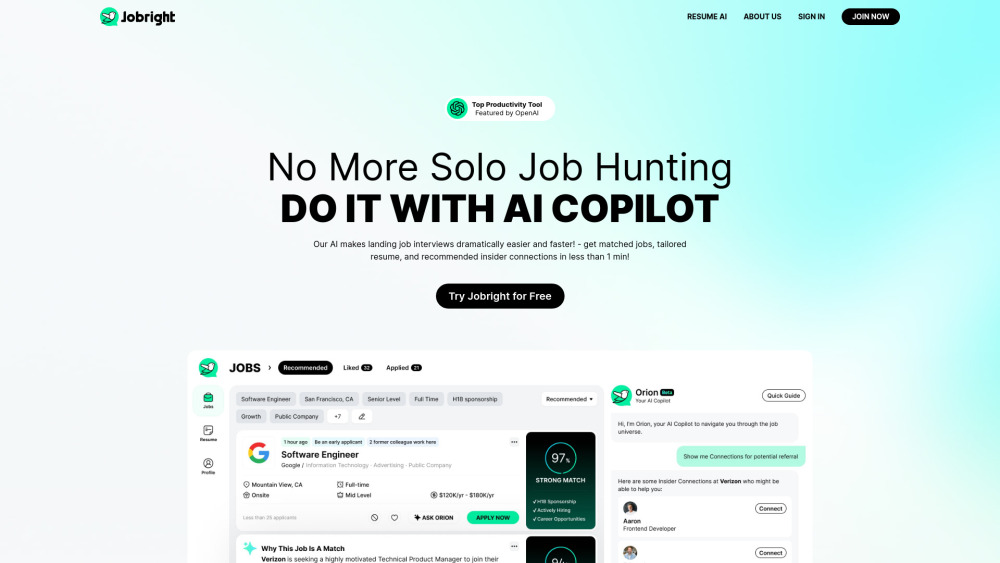
AIを活用したジョブサーチコパイロットでキャリアの可能性を引き出そう
今日の競争が激しい職場環境では、適切なポジションを見つけることは容易ではありません。そこで登場するのがAIジョブサーチコパイロットです。これは、あなたのスキル、好み、キャリア目標を分析することで、職探しを支援するインテリジェントなアシスタントです。この革新的なツールは、あなたの期待にぴったり合ったカスタマイズされた職業推薦を提供します。時間を節約し、夢の仕事を得る可能性を高めるパーソナライズされた提案で、職探しを効率化しましょう。
Find AI tools in YBX
