アップルの新しい「MM1」AIモデルを探る:特徴、応用、革新の全貌
Most people like

風水のエネルギーを活用し、調和のとれた豊かな生活を実現しましょう。これらの原則を理解し実践することで、あなたの住環境を安らぎとポジティブなエネルギーの源に変えることができます。
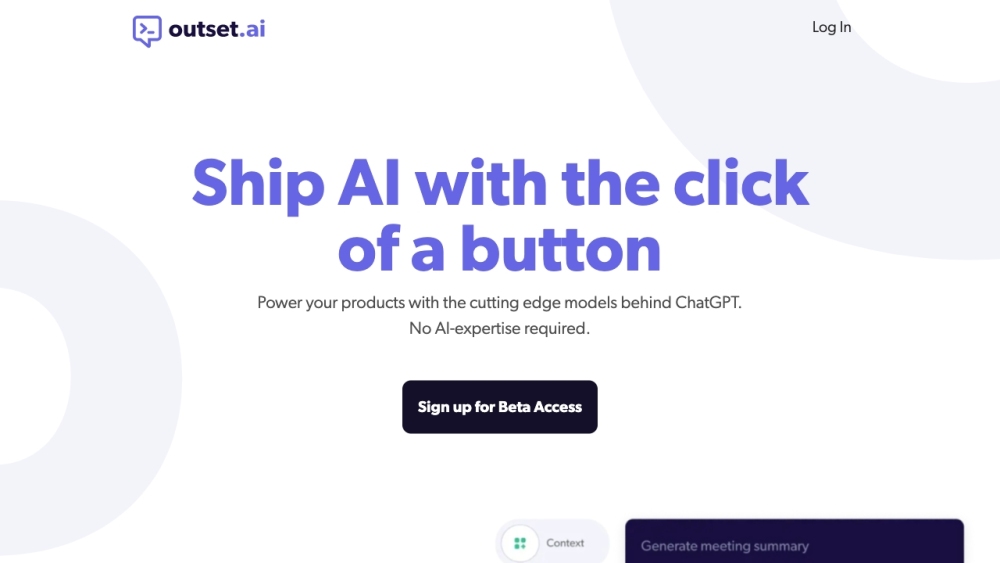
Outset.aiをご紹介します。これは、シームレスな自動インタビューと実用的な洞察を提供する革新的なAIプラットフォームです。Outset.aiと共にデータ収集と分析の未来を体験し、効率と知性が融合する世界へようこそ。
Find AI tools in YBX
Related Articles
Refresh Articles