A Stability AI Lança o Stable Audio: Uma Revolução para Profissionais de Design de Som
Most people like

Descubra o poder dos vídeos personalizados gerados por IA, que atendem às preferências e necessidades únicas de cada cliente. Eleve sua estratégia de marketing ao engajar seu público com conteúdo sob medida que ressoe e cative, garantindo uma experiência memorável para cada espectador. Desbloqueie o potencial de soluções de vídeo customizadas para aumentar a satisfação do cliente e impulsionar as conversões.
Salve e organize suas valiosas notas, imagens, citações e destaques de forma simples usando a plataforma segura e alimentada por IA do mymind, projetada para acesso e recuperação fáceis.
Desbloqueie o poder de fórmulas precisas impulsionadas por IA para Excel e Google Sheets. Aproveite algoritmos avançados para elevar sua análise de dados, otimizar cálculos e aumentar a produtividade nas suas tarefas de planilhas.
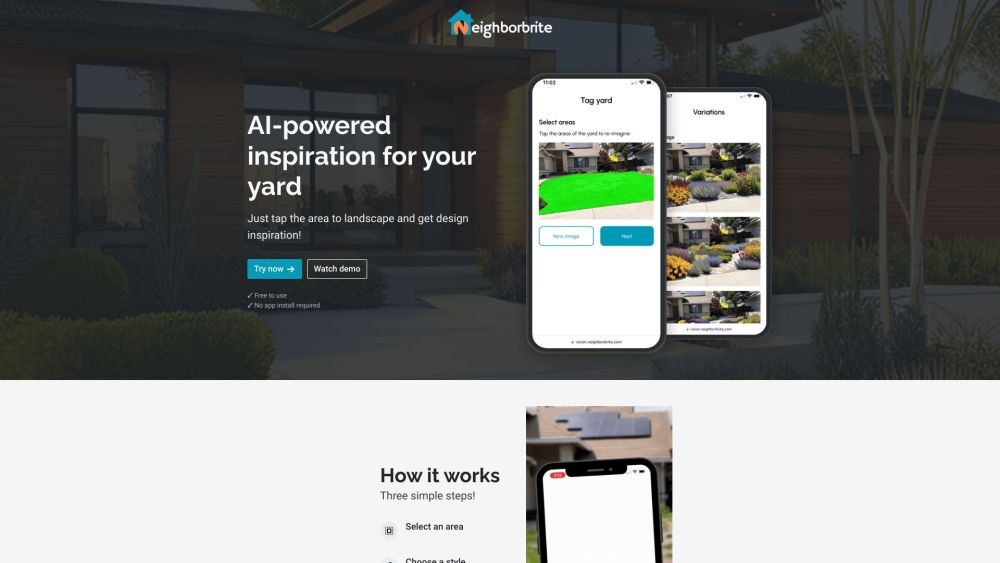
Transforme seu espaço ao ar livre com inspiração impulsionada por IA para o seu jardim. Descubra ideias inovadoras e designs personalizados para aprimorar sua paisagem e criar o refúgio perfeito. Deixe a tecnologia de ponta guiá-lo na elaboração do seu jardim dos sonhos hoje mesmo!
Find AI tools in YBX
Related Articles
Refresh Articles