O mais recente modelo de vídeo com IA da Microsoft avança na tecnologia de geração baseada em trajetórias.
Most people like
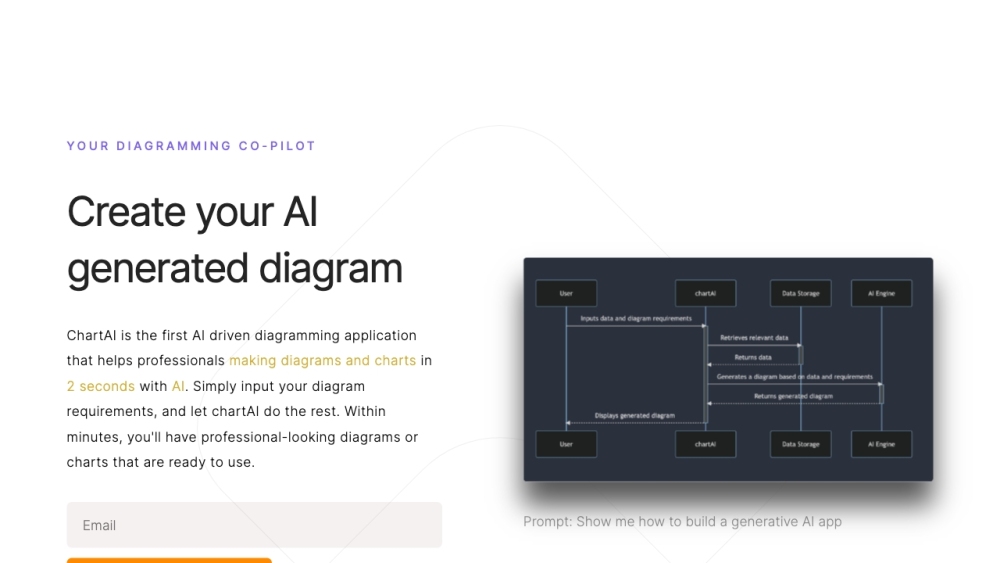
ChartAI aproveita o poder do ChatGPT para ajudar os usuários a criar e interpretar gráficos e diagramas com facilidade. Com uma funcionalidade intuitiva, o ChartAI transforma dados complexos em representações visuais envolventes e compreensíveis, aprimorando sua experiência de análise de dados.
Apresentamos nossa plataforma inovadora de geração de fotos e avatares com inteligência artificial, onde inovação se encontra com criatividade! Com tecnologia avançada ao seu alcance, os usuários podem criar imagens e avatares personalizados de forma descomplicada. Se você deseja aprimorar sua presença online, criar gráficos únicos para redes sociais ou simplesmente explorar seu potencial criativo, nossa plataforma transforma suas ideias em visuais de alta qualidade em minutos. Mergulhe em um mundo de possibilidades e descubra como é fácil gerar fotos e avatares cativantes adaptados ao seu estilo!
Descubra o poder de um modelo de IA que transforma solicitações de texto em imagens deslumbrantes. Aproveitando algoritmos avançados, esta ferramenta inovadora permite que os usuários visualizem suas ideias e conceitos de uma maneira nunca vista antes. Seja você um artista em busca de inspiração ou uma empresa que deseja aprimorar seu conteúdo, nosso gerador de imagens baseado em IA abre um mundo de possibilidades criativas. Desperte sua imaginação e deixe a tecnologia dar vida às suas palavras!
Você é uma startup que busca elevar sua marca com um design excepcional? Uma assinatura de design pode oferecer acesso contínuo a serviços criativos profissionais adaptados às suas necessidades em evolução. Essa abordagem inovadora não apenas economiza tempo e dinheiro, mas também garante que sua marca permaneça atual e competitiva no mercado dinâmico de hoje. Descubra como uma assinatura de design pode ser a mudança de jogo que sua startup precisa para cativar visualmente seu público e impulsionar o crescimento.
Find AI tools in YBX
Related Articles
Refresh Articles