Alibaba представила Qwen2-VL — новую модель ИИ, способную анализировать видео продолжительностью более 20 минут.
Most people like
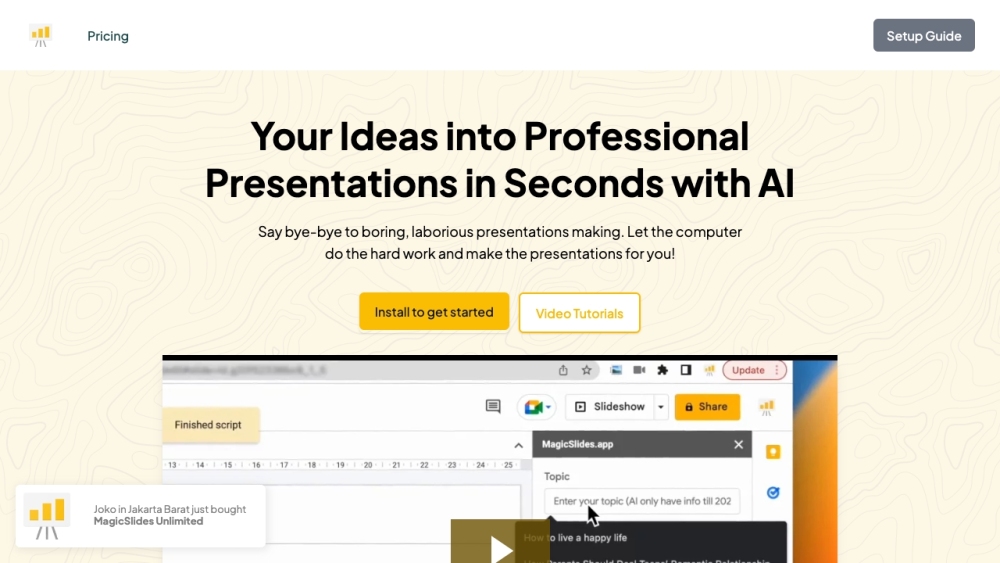
MagicSlides использует возможности искусственного интеллекта для создания потрясающих слайдов презентаций из любого текстового ввода. Превратите свои идеи в захватывающие визуальные презентации без усилий!

Denvr Dataworks специализируется на предоставлении надежных облачных и инфраструктурных решений, адаптированных для искусственного интеллекта (ИИ), машинного обучения (МО), высокопроизводительных вычислений (ВПВ) и различных вычислительных приложений.
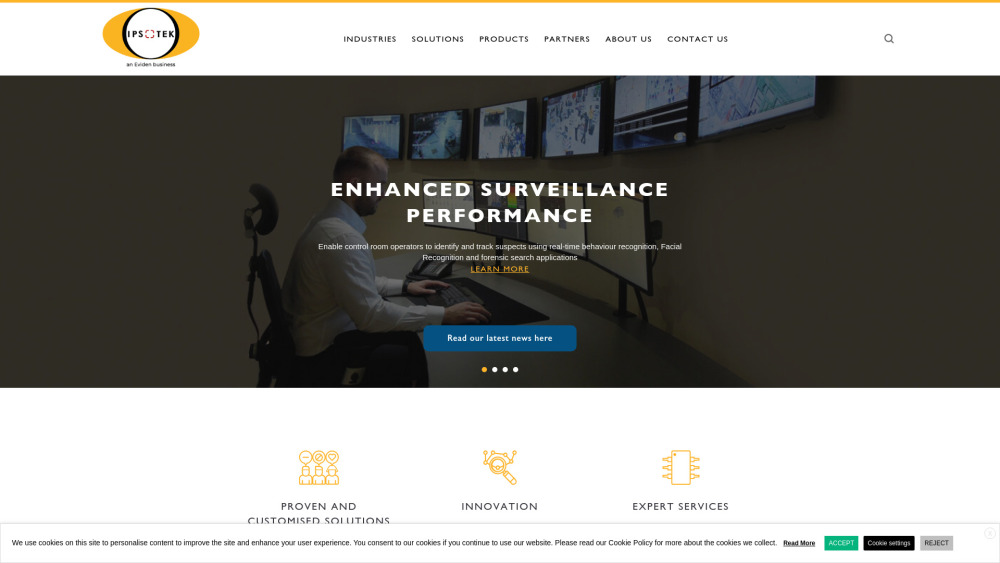
Представляем ведущего поставщика решений по аналитике видео на основе искусственного интеллекта, который стремится преобразовать визуальные данные в действенные инсайты. Наша инновационная технология использует передовые алгоритмы для повышения безопасности, оптимизации операций и принятия обоснованных решений. Присоединяйтесь к нам в переосмыслении того, как компании используют видеоданные для повышения эффективности и безопасности в современном динамичном окружении.
Углубите своё понимание музыки и оптимизируйте организацию с нашим полным руководством. Откройте для себя эффективные техники, которые не только прояснят ваш музыкальный опыт, но и помогут эффективно управлять вашей музыкальной коллекцией. Независимо от того, являетесь ли вы начинающим музыкантом или заядлым слушателем, овладение этими стратегиями преобразит ваш подход к музыке и удовольствие от неё.
Find AI tools in YBX
Related Articles
Refresh Articles