Anthropic запускает награды в $15,000 для хакеров в усилиях по повышению безопасности ИИ.
Most people like
Введение:
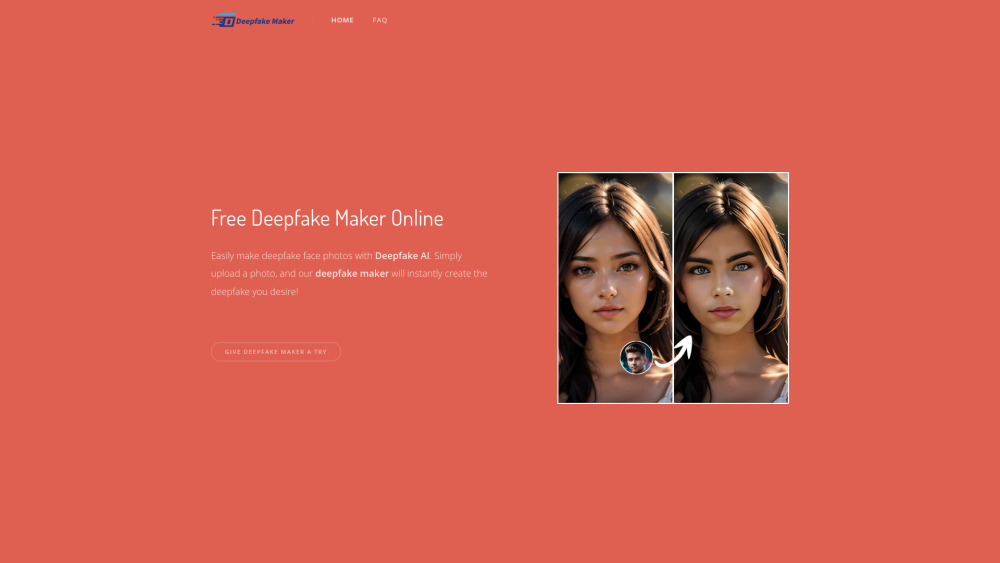
Откройте для себя универсальный онлайн-инструмент для легкого создания реалистичных фейковых обменов лицами. Если вы хотите улучшить свой видеоконтент, создать увлекательные визуалы или исследовать захватывающий мир технологий дипфейк, наша удобная платформа позволяет вам без усилий и convincingly менять лица. Погрузитесь в увлекательные возможности создания дипфейков уже сегодня!
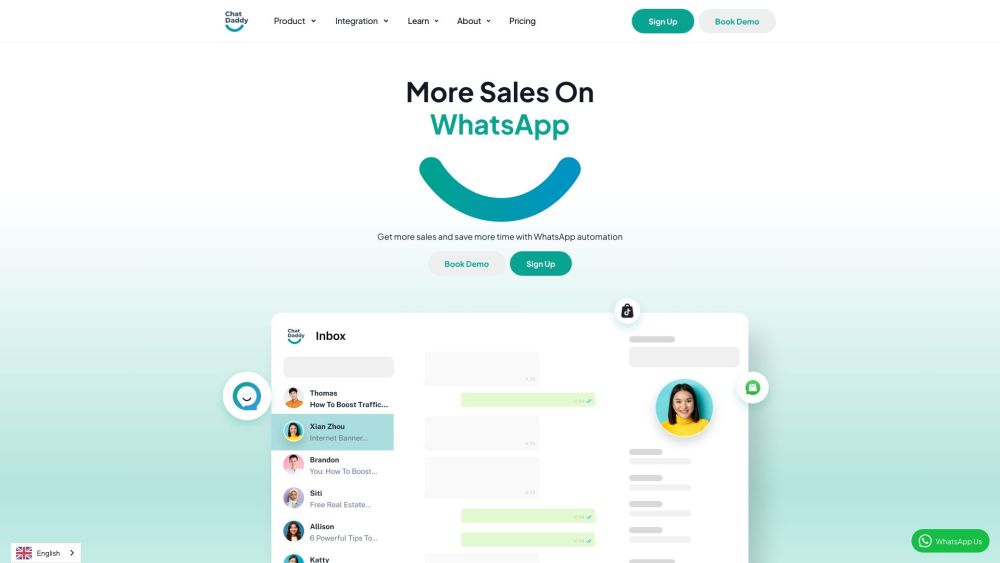
Преобразите свой бизнес с помощью мощного инструмента автоматизации WhatsApp: экономьте время и повышайте эффективность.
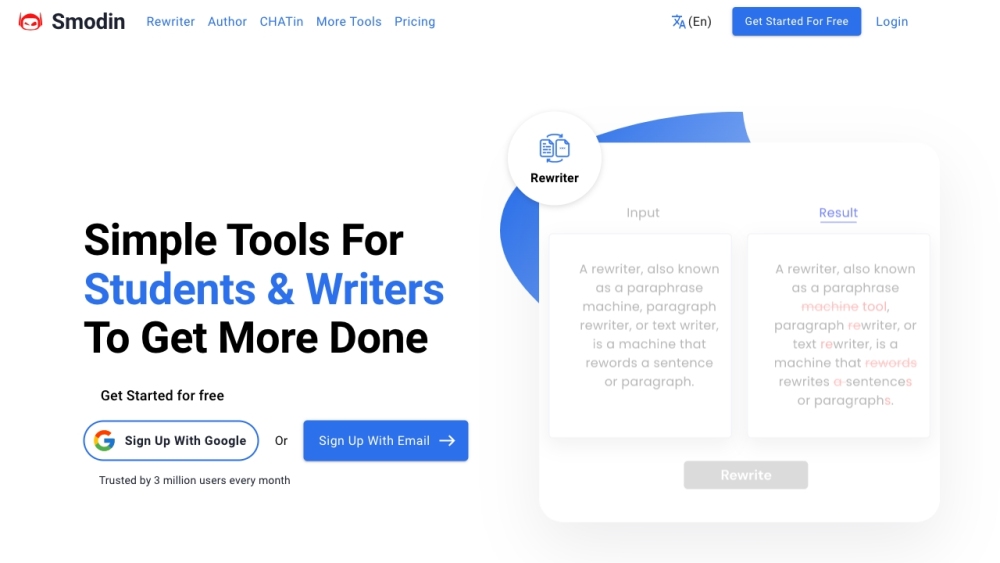
Smodin — это инновационная платформа, предназначенная для улучшения навыков письма с помощью различных инструментов, адаптированных для студентов, профессионалов и создателей контента по всему миру.

В современном конкурентном ландшафте эффективный поиск и анализ патентов на глобальном уровне играют ключевую роль в стимулировании инноваций и защите интеллектуальной собственности. Систематически собирая и исследуя данные о патентах со всего мира, компании и исследователи могут выявлять тенденции, раскрывать конкурентную информацию и принимать обоснованные решения. Этот процесс не только улучшает стратегическое планирование, но и способствует росту, следя за технологическими достижениями и изменениями на рынке. Присоединяйтесь к нам в изучении основных методов и инструментов для навигации по сложностям глобальной патентной информации, чтобы укрепить вашу инновационную стратегию.
Find AI tools in YBX
Related Articles
Refresh Articles