Perplexity анонсирует запуск программы распределения доходов с веб-публикаторами в следующем месяце.
Most people like
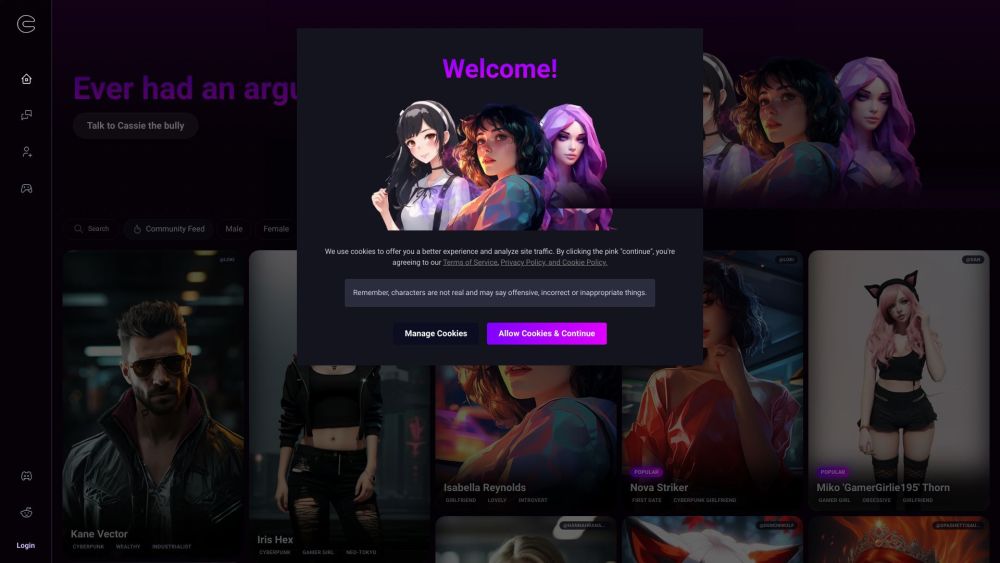
Откройте для себя, взаимодействуйте и наслаждайтесь миром ИИ-персонажей. Развивайте свое творчество и соединяйтесь с инновационными виртуальными личностями для увлекательного опыта!

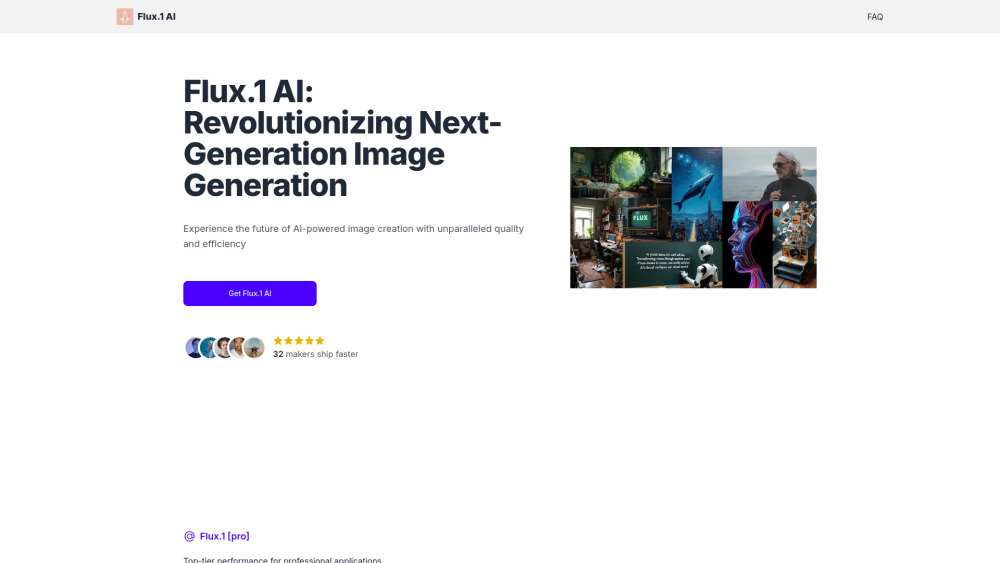
Исследуйте передовой мир современных технологий ИИ, созданных для генерации потрясающих изображений на основе текста. Этот инновационный подход использует мощные алгоритмы и методы глубокого обучения для преобразования письменных описаний в яркие визуальные представления. Независимо от того, являетесь ли вы художником, дизайнером или просто интересуетесь потенциалом ИИ, этот исчерпывающий гид освещает возможности и применение генерации изображений из текста, показывая, как это революционизирует креативность и производство контента.
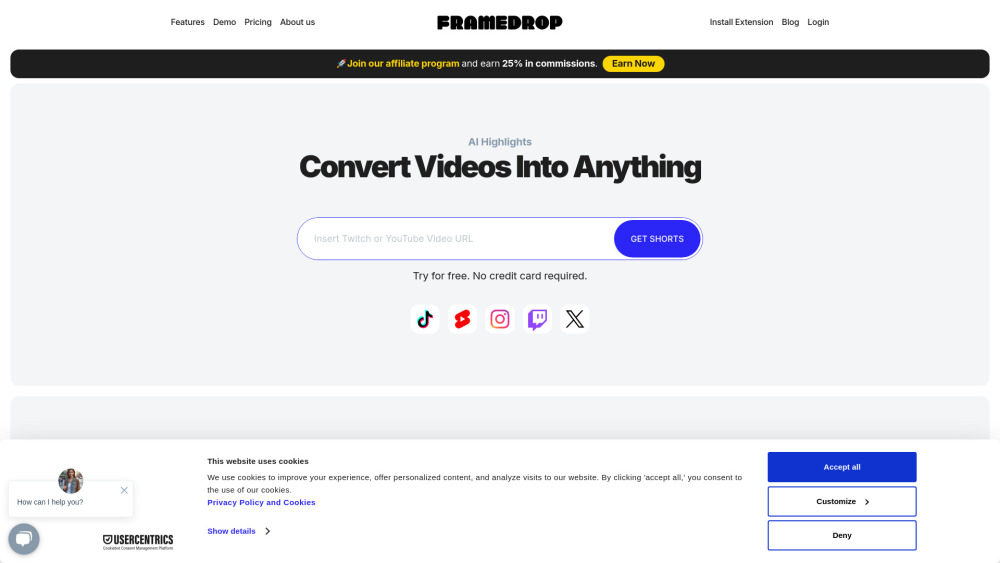
Ищете AI-инструмент, который без усилий превращает видео в увлекательный короткий контент? Узнайте, как это инновационное решение может улучшить вашу стратегию видеомаркетинга, упростить процесс создания контента и эффективно привлечь вашу аудиторию. Исследуйте преимущества использования AI-технологий для преобразования длинных видео в лаконичные, эффектные клипы, которые находят отклик у зрителей.
Find AI tools in YBX
Related Articles
Refresh Articles