Discover Best AI Tools for Private AI
This page shows you the best Private AI tool in AI websites and tools, and free Private AI tool in AI.
The best ai tools for Private AI are: Venice AI , Offline Chat: Private AI
Brainstorm, summarize documents, research, write, and edit your text in seconds with private and uncensored AI chat models.
Venice never sees or stores your prompts or responses.
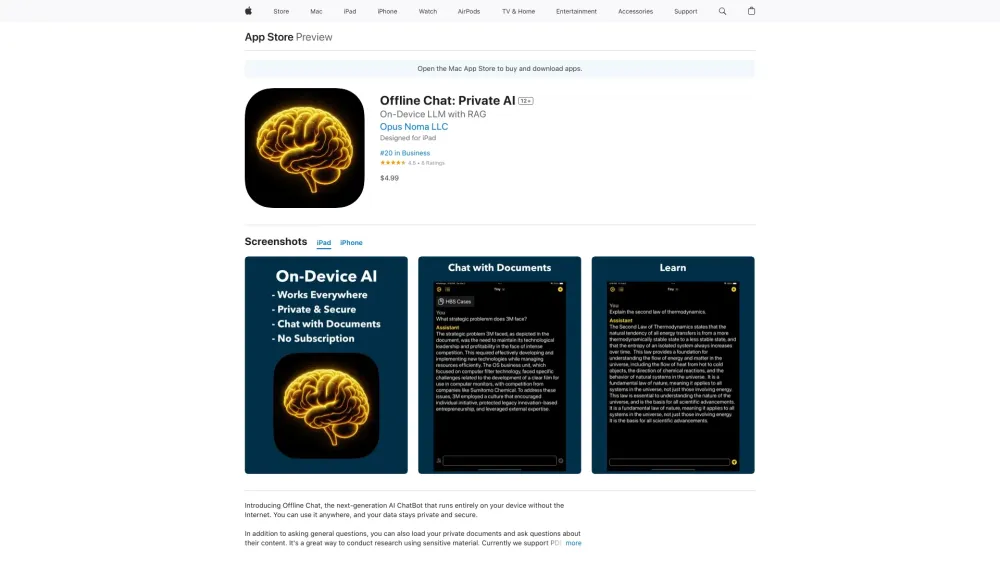
In today's digital landscape, the integration of On-Device Large Language Models (LLMs) combined with Retrieval-Augmented Generation (RAG) technology represents a significant breakthrough in artificial intelligence. This innovative approach not only enhances the capabilities of AI systems but also ensures that they operate efficiently at the edge, minimizing latency and maximizing performance. As we explore the intersection of on-device processing and RAG, you'll discover how this synergy transforms user experiences and drives intelligent solutions across various applications. Join us in diving deeper into this revolutionary technology!