Meta和Google研究人員的新數據管理方法可能徹底改變自我監督學習技術
Most people like

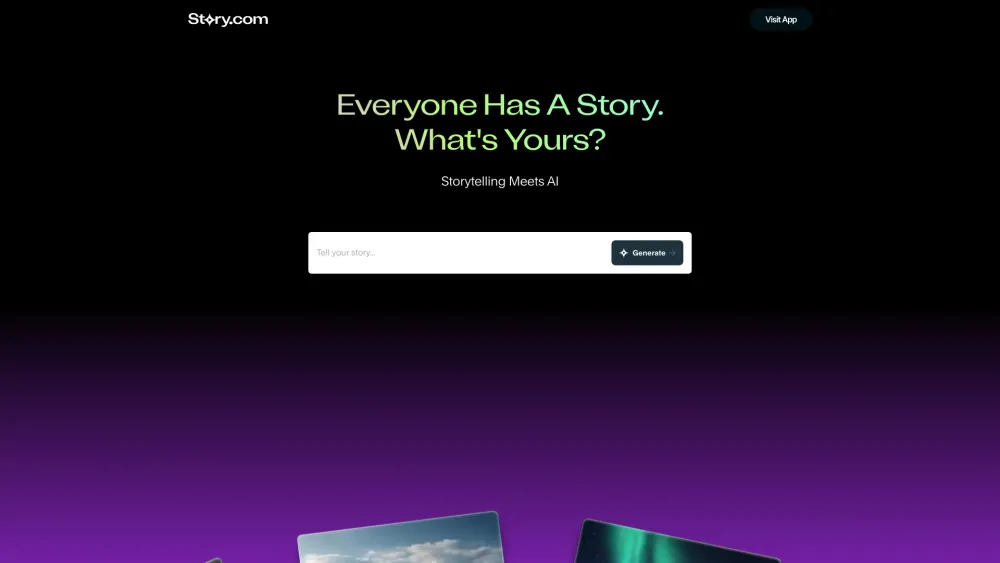
釋放您的創意,打造並分享引人入勝的 AI 生成影片故事。探索人工智慧的力量,將您的想法轉化為視覺驚豔的敘事,與觀眾產生共鳴。無論是用於個人表達還是專業講述,我們的平台使您能輕鬆實現您的願景。立即投入 AI 影片創作的世界吧!
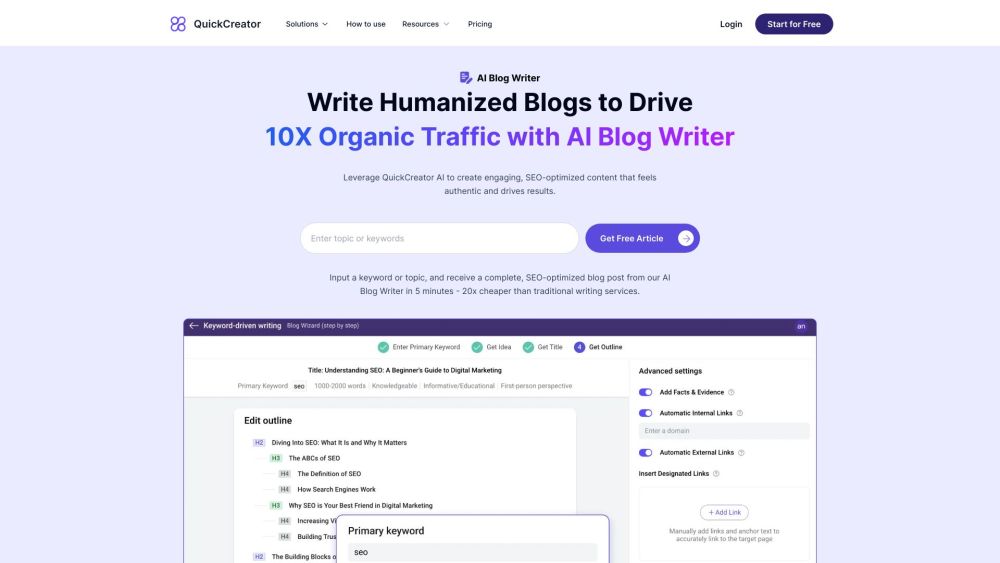
在當今競爭激烈的線上環境中,創造引人入勝且經過SEO優化的部落格內容對於提升流量和增加可見性至關重要。利用人工智慧的力量,您可以輕鬆生成高品質的部落格文章,這些文章不僅能與讀者產生共鳴,還能在搜尋引擎中獲得良好排名。了解 AI 驅動的工具如何簡化您的內容創作過程,讓您專注於推動在線成功的策略。
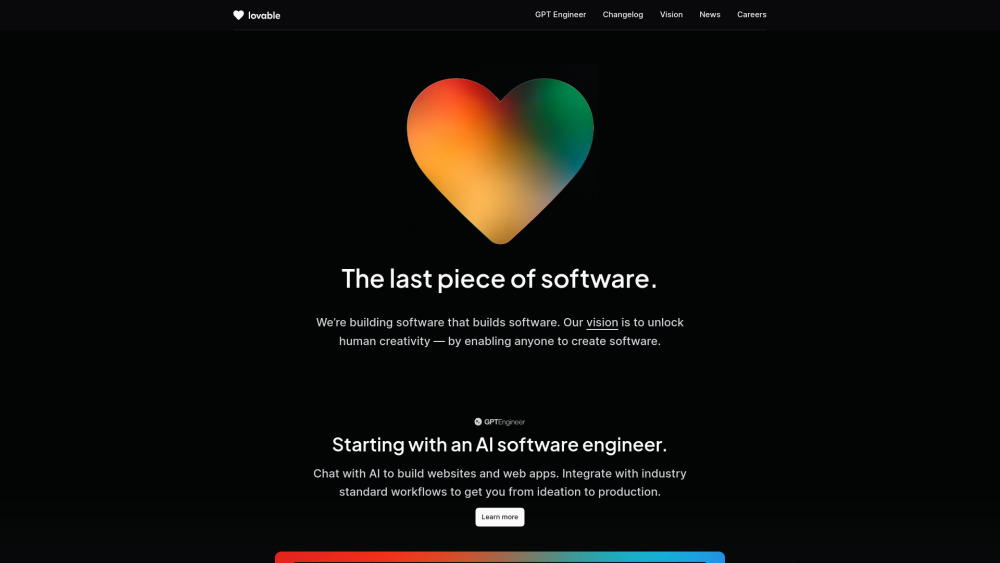
探索一款創新的AI工具,旨在通過對話互動輕鬆構建和部署網頁應用程式。這個易於使用的解決方案利用人工智慧的力量,簡化您的網頁開發流程,使其對新手和經驗豐富的開發者同樣可及。參與直觀的對話,輕鬆將您的想法轉化為功能齊全的應用程式。
Find AI tools in YBX
Related Articles
Refresh Articles