Patronus AI 識別出主要人工智慧系統中「令人擔憂」的安全漏洞
Most people like

在當今的數位時代,人工智慧動畫技術正在徹底改變我們體驗靜態影像的方式。藉由運用先進的演算法,日常照片可以轉化為生動的動畫,為珍貴的回憶注入活力。這一創新過程不僅提升了視覺敘事的效果,還為藝術家、行銷人員和攝影師提供了無限的創作可能性。探索人工智慧動畫技術如何重塑視覺內容的世界,提升我們與靜態影像的連結方式。

提升您的健康之旅,搭配 AI 驅動的個人教練
體驗前所未有的個性化健身與健康方案。我們的 AI 個人教練根據您的需求量身定制運動計劃和健康方案,確保您獲得最佳成果並提升整體健康。今天就來探索健康指導的未來吧!
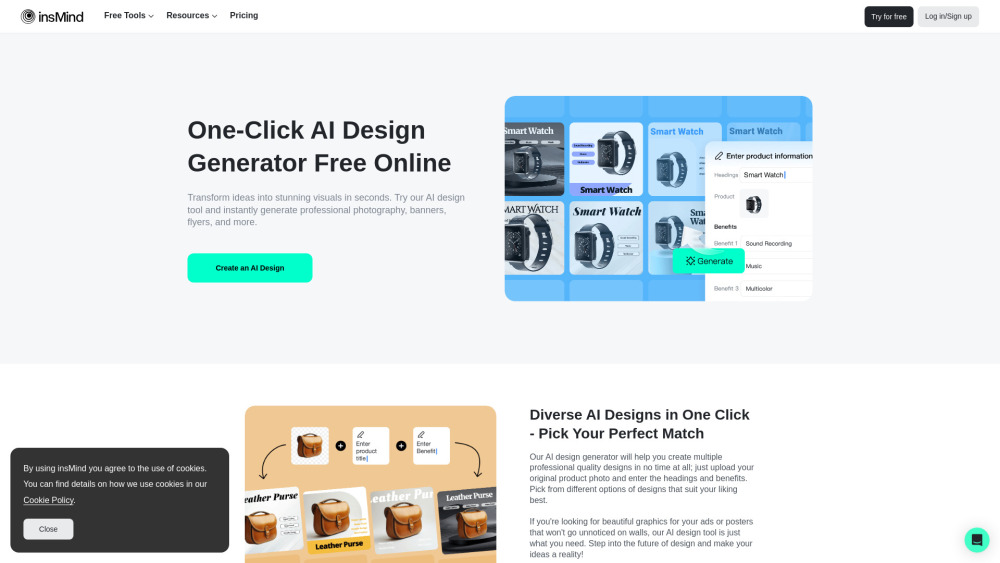
使用 insMind AI 設計生成器來釋放您的創造力——這是一個強大的工具,讓您能夠免費創建專業品質的圖形設計。只需一鍵,您便可以輕鬆生成專為行銷、推廣及商業需求而設計的卓越 AI 驅動作品,節省聘請設計師的麻煩與開支。立即開始使用 AI 創造引人注目的設計吧!
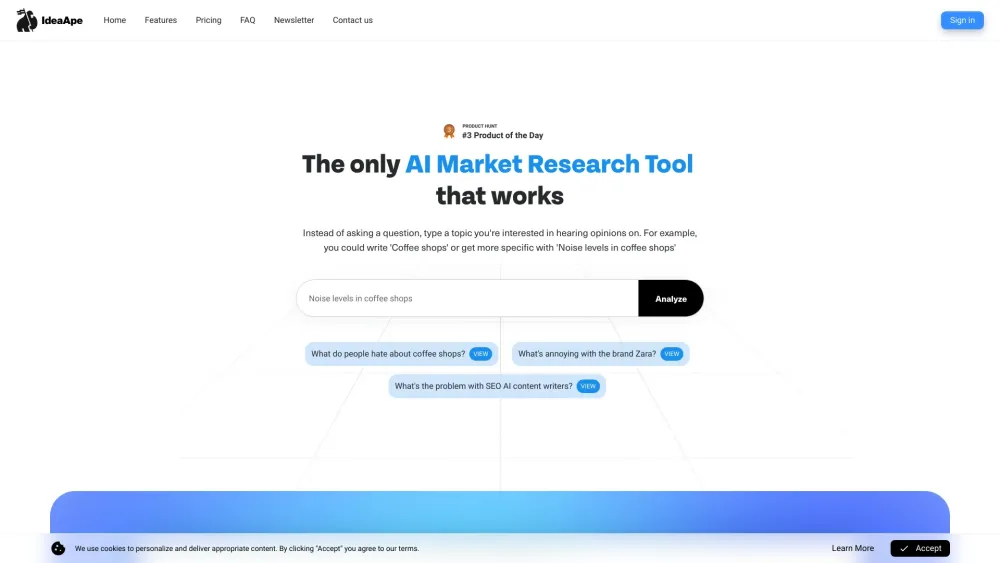
探索專為進階用戶與初學者設計的終極 AI 市場研究工具。我們的創新平台結合尖端技術與友善使用者介面,輕鬆收集洞察並分析市場趨勢。立即體驗 AI 驅動研究的力量,提升您的決策過程!
Find AI tools in YBX
Related Articles
Refresh Articles