جوجل تطلق سلسلة Gemma 2: التعريف بنموذج بـ 27 مليار معلمة قادر على التشغيل باستخدام وحدة معالجة TPU واحدة فقط.
Most people like
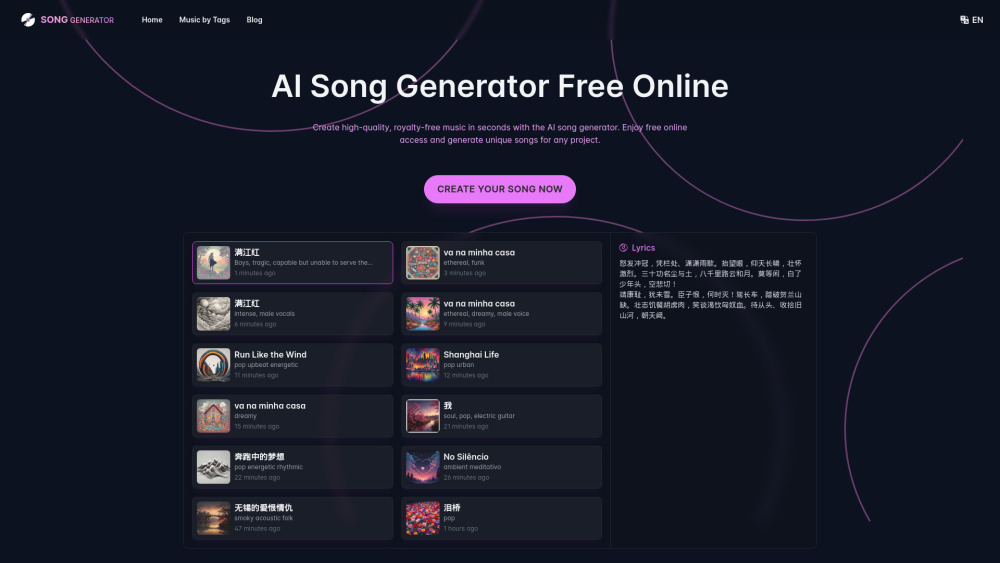
حوّل النص بسرعة إلى موسيقى خالية من حقوق الملكية باستخدام الذكاء الاصطناعي لمشاريعك
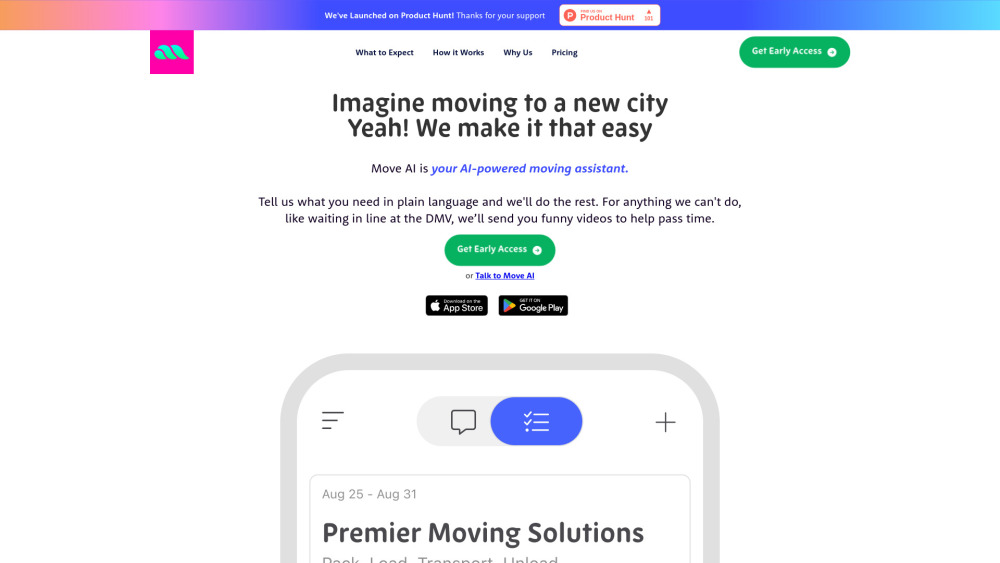
هل تشعر بالارتباك بسبب فكرة الانتقال القادم؟ تم تصميم مساعدنا الذكي المدعوم بالذكاء الاصطناعي لتبسيط عملية الانتقال، مما يجعلها أسهل وأكثر كفاءة. بدءًا من تنظيم مهام الانتقال وصولاً إلى العثور على أفضل الخدمات التي تناسب احتياجاتك، تقدم منصتنا الذكية دعمًا شخصيًا في كل خطوة. ودع الفوضى المرتبطة بالانتقال واستمتع بتجربة أكثر سلاسة ومتعة مع تقنيتنا المبتكرة. دعنا نساعدك في تحويل انتقالك إلى انتقال سلس.
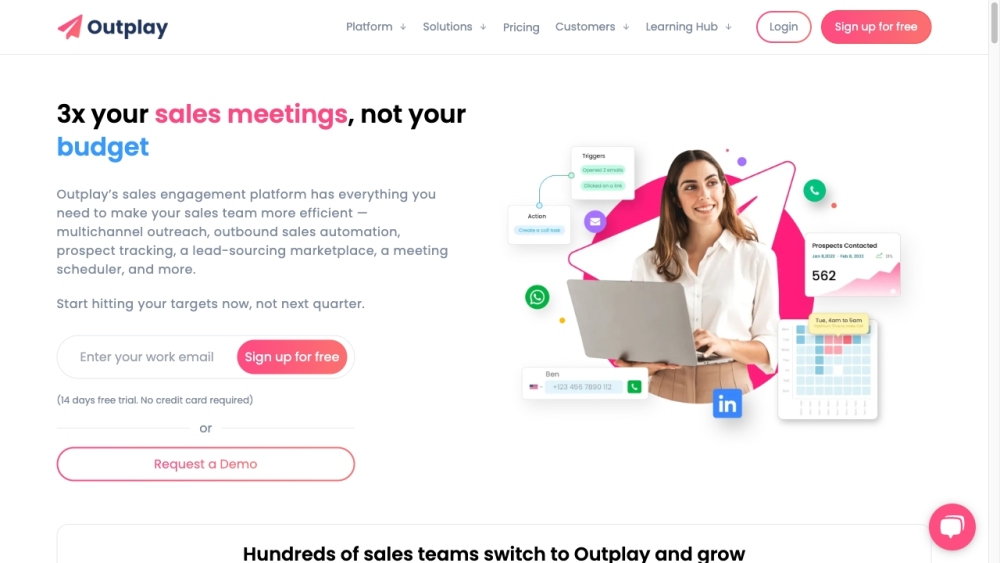
Outplay تمكّن فرق المبيعات من تحسين إتمام الصفقات وزيادة الإيرادات من خلال أتمتة متقدمة مدعومة بالذكاء الاصطناعي ودمج سلس مع نظم إدارة علاقات العملاء.
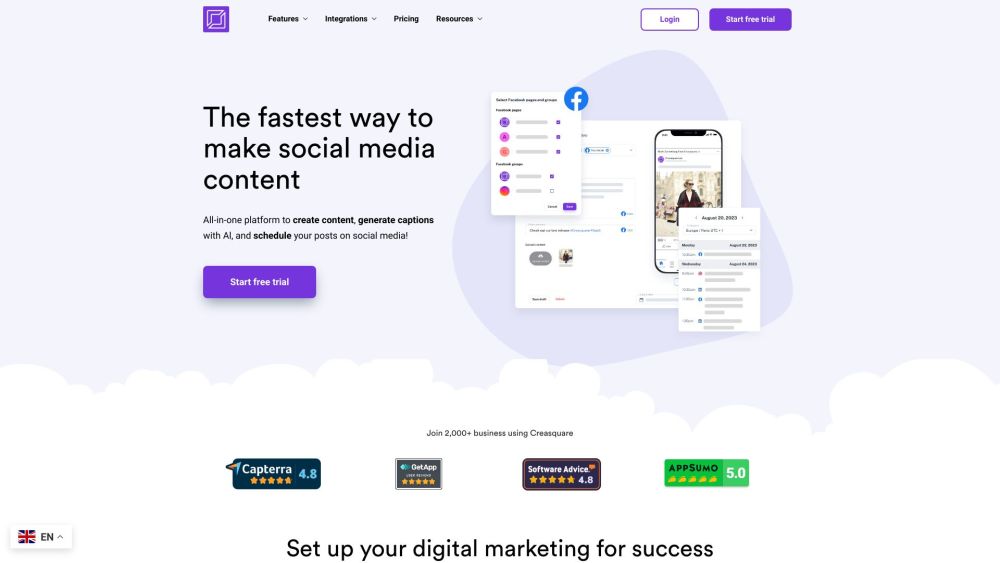
تقدم كرياسكوير حلاً قويًا للمحتوى الرقمي مدفوعًا بالذكاء الاصطناعي، الذي يُبسِط عملية إنشاء المحتوى، وجدولته، وتحليلاته، وتكامل وسائل التواصل الاجتماعي. استمتع بتفاعل سلس وأداء محسن لوجودك على الإنترنت من خلال منصة كرياسكوير المبتكرة.
Find AI tools in YBX
Related Articles
Refresh Articles