Anthropics Claude 3 Erkennung: Wie es Forschungstests identifizierte
Most people like

Verleihen Sie Ihrem Look sofort einen Auftrieb mit der Xpression Camera-App, die dafür entwickelt wurde, Ihr Erscheinungsbild in Echtzeit zu verändern. Verbessern Sie mühelos Ihre Fotos und Videos und entdecken Sie unzählige Möglichkeiten der Selbstentfaltung!
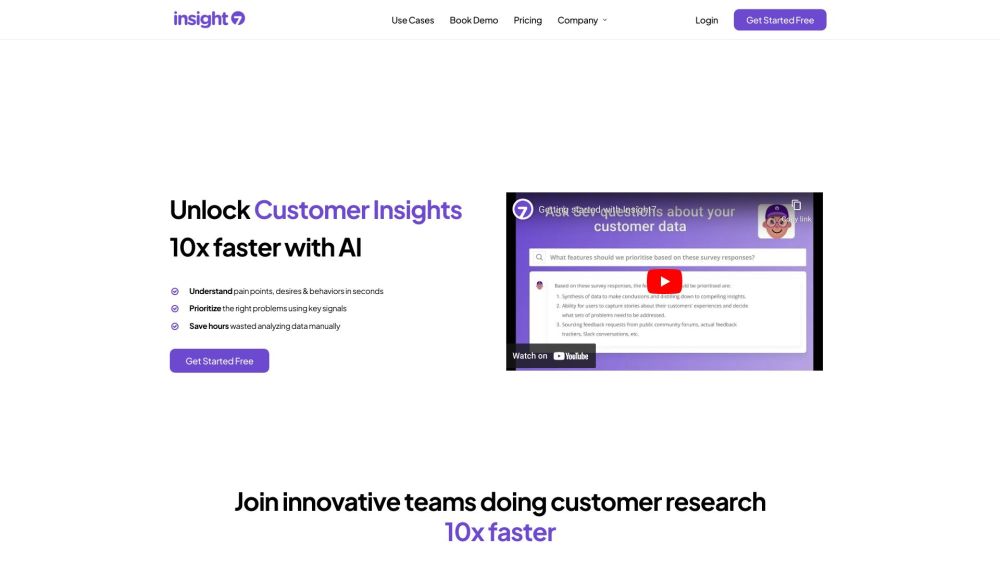
Willkommen bei Insight7, der innovativen KI-Plattform zur Automatisierung der Kundenanalyse. Durch die Optimierung dieses Prozesses spart Insight7 nicht nur wertvolle Zeit, sondern deckt auch verborgene Wachstumschancen auf. Erfahren Sie, wie Insight7 Ihren Umgang mit Datenanalysen revolutionieren und Ihre Entscheidungsfindung verbessern kann.
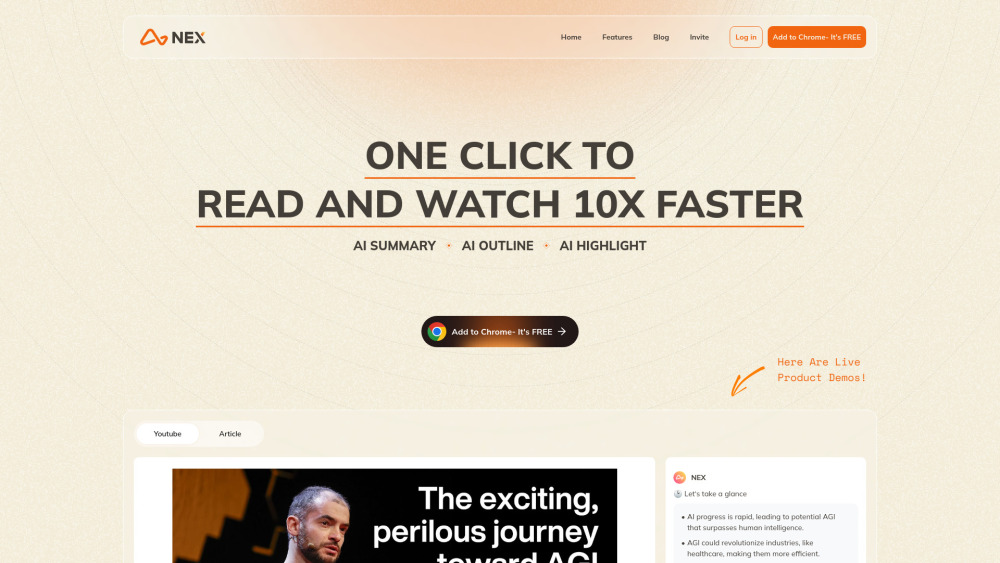
Präsentation unseres KI-gestützten Zusammenfassungs- und Gliederungsgenerators – speziell für YouTube-Videos und Artikel entwickelt! Dieses innovative Tool optimiert die Inhaltsproduktion, indem es prägnante Zusammenfassungen und strukturierte Gliederungen bereitstellt, wodurch es kreatoren und Vermarktern erleichtert wird, ihre Videos und Artikel zu verbessern. Steigern Sie Ihre Content-Strategie, verbessern Sie die Zuschauerinteraktion und sparen Sie Zeit mit unseren fortschrittlichen Funktionen, die auf optimale SEO-Leistung zugeschnitten sind. Beginnen Sie noch heute mit dem Erstellen von überzeugenden Zusammenfassungen und Gliederungen!
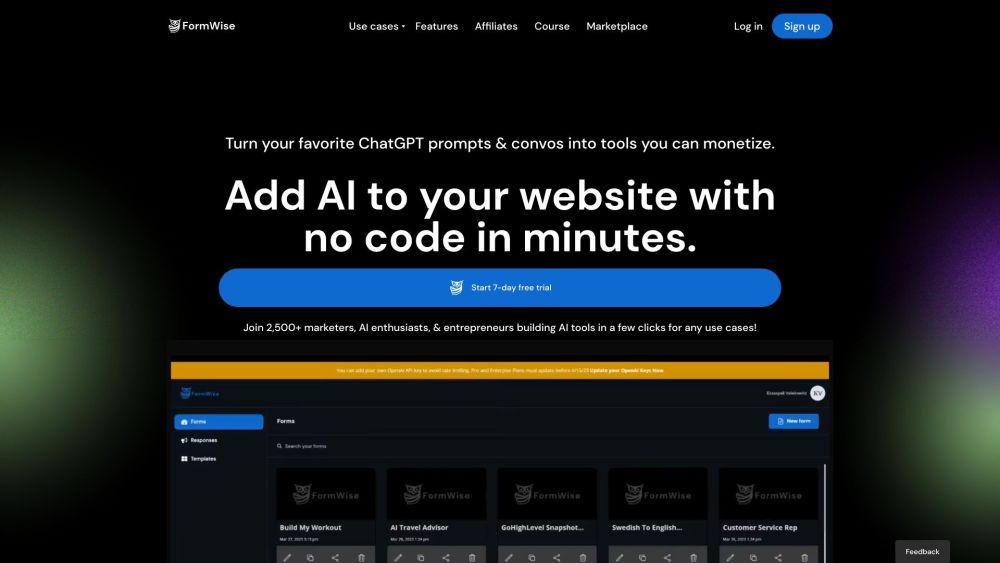
Entdecken Sie, wie FormWise.AI es Nutzern ermöglicht, mühelos KI-Tools zu erstellen, anzupassen und zu monetisieren – ganz ohne Programmierkenntnisse.
Find AI tools in YBX
Related Articles

Refresh Articles