AppleがAI機能を発表:新モデルがMistralとHugging Faceの性能を超える
Most people like
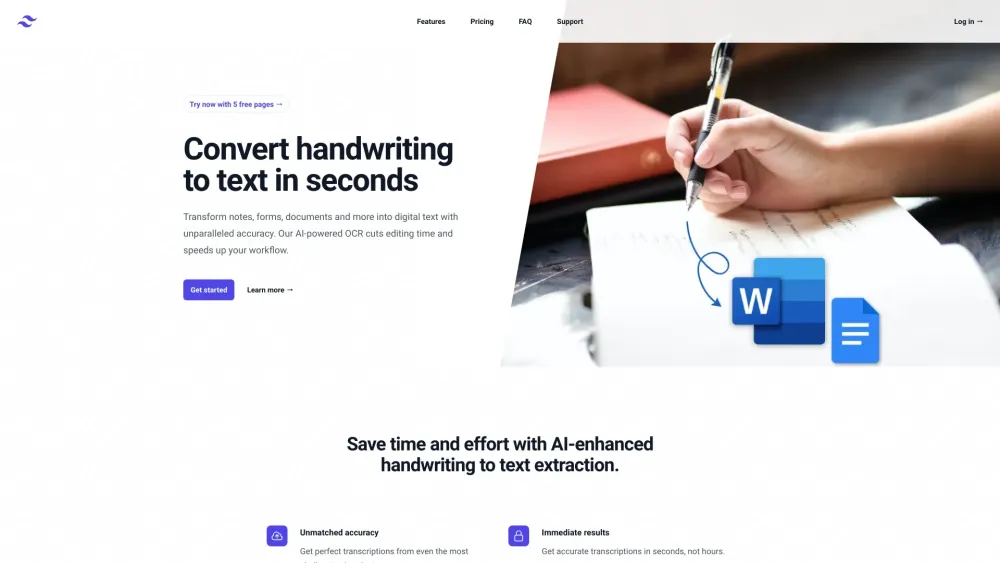
手書きのコンテンツを正確にデジタル形式に変換
今日の急速に進化するデジタル世界では、手書きのコンテンツをデジタル形式に変換することがこれまで以上に重要です。メモを保存したり、スケッチをデジタルグラフィックに変換したり、文書を効率化したりする際、手書きの資料を正確にデジタル化することが、効率とアクセス性を向上させるために不可欠です。技術の力を活用して、手書きのコンテンツを簡単に検索、編集、共有できるようにし、貴重な情報が常に手元にあることを確保しましょう。
スキルギャップを埋め、人材の変革を推進するために、SkillsoftのAI搭載学習プラットフォームを活用しましょう。最先端のテクノロジーを利用した、効果的な結果をもたらすダイナミックな社員育成アプローチを体験してください。
今日のデジタル時代において、効果的なコミュニケーションは極めて重要です。私たちのAIによるテキスト変換ツールは、複雑な技術的な文章を明確で親しみやすい言葉に変換し、誰でも理解できるようにします。学生、プロフェッショナル、コンテンツクリエイターの皆さん、このツールを使えば、あなたのメッセージが聴衆に響くような文章を作成できます。意図した意味を保ちながら、言葉を簡素化する力を体験してください!
Find AI tools in YBX
Related Articles
Refresh Articles