A NVIDIA Revela Novo Modelo de IA de 8B: Alta Precisão e Eficiência, Compatível com Estações de Trabalho RTX
Most people like
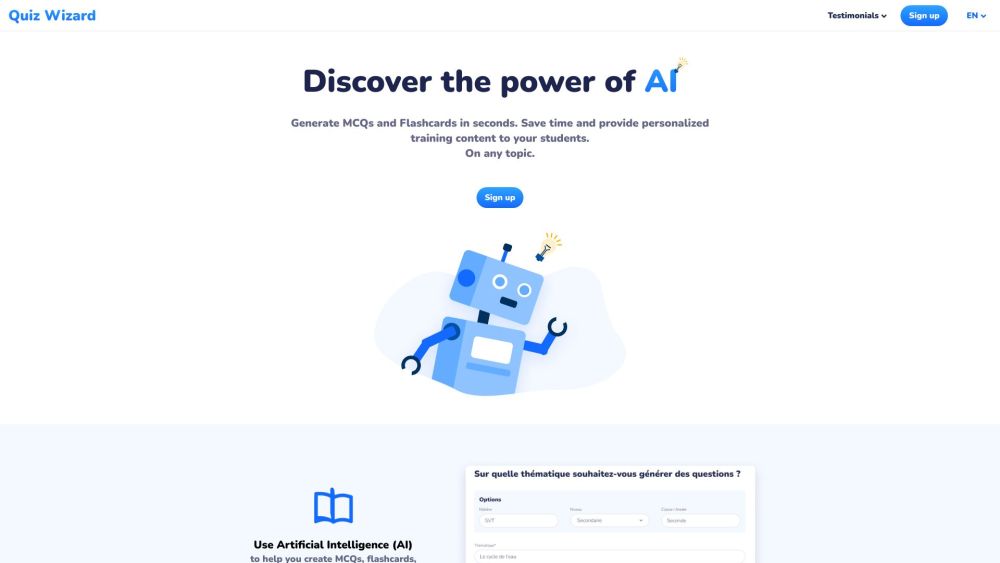
O Quiz Wizard é uma plataforma inovadora movida por IA, projetada para criar questões de múltipla escolha personalizadas e recursos de estudo sob medida.

No dinâmico cenário digital de hoje, os agentes de atendimento ao cliente desempenham um papel crucial na satisfação do cliente. No entanto, lidar com consultas complexas pode ser desafiador sem suporte imediato. Nossa Plataforma de Orientação em Tempo Real capacita os centros de contato, oferecendo aos agentes assistência instantânea e sensível ao contexto, garantindo que forneçam respostas precisas e pontuais. Ao aproveitar análises avançadas e insights impulsionados por IA, esta plataforma melhora o desempenho dos agentes, otimiza as interações com os clientes e, em última análise, aumenta a produtividade geral do seu centro de contato. Experimente o futuro do atendimento ao cliente hoje!
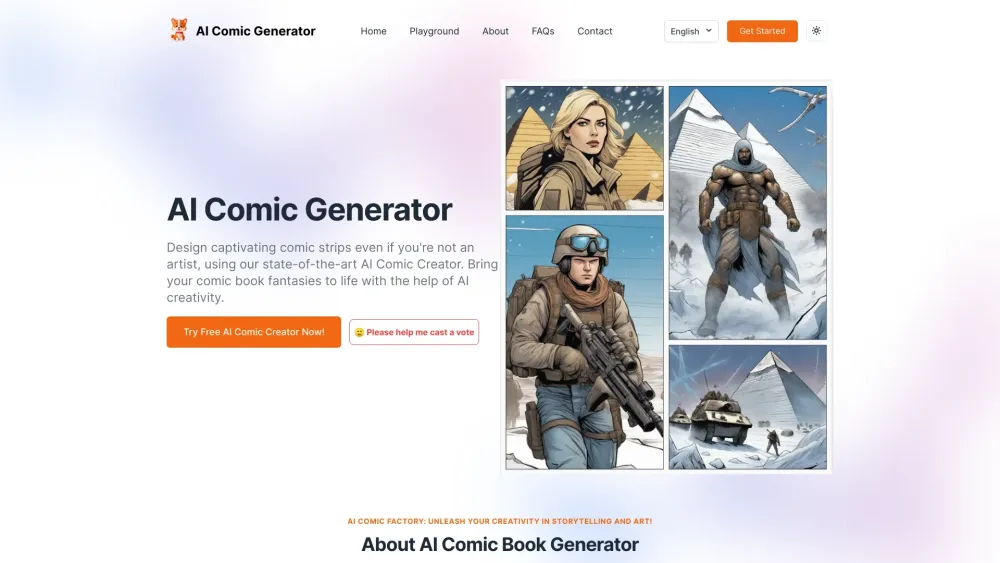
Desperte sua criatividade e aprenda a criar quadrinhos cativantes utilizando a tecnologia de IA. Descubra as ferramentas e técnicas inovadoras que facilitam mais do que nunca dar vida à sua visão narrativa, aproveitando o poder da inteligência artificial. Abrace o futuro dos quadrinhos e comece sua jornada artística hoje mesmo!
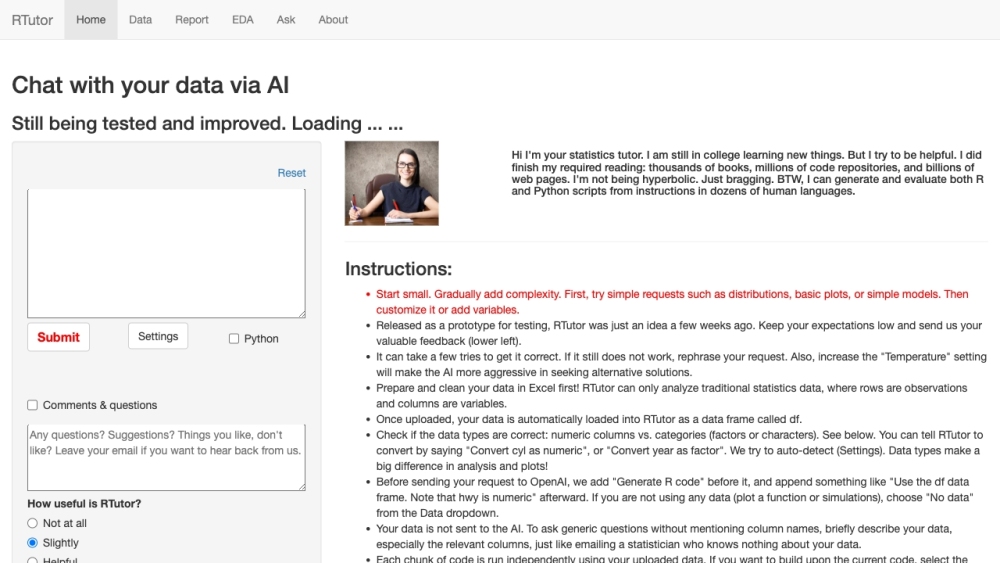
RTutor é um aplicativo inovador impulsionado por IA, projetado para facilitar a análise de dados por meio do processamento de linguagem natural.
Find AI tools in YBX
Related Articles
Refresh Articles