Meta推出了變色龍:一款頂尖的多模態模型,革新人工智慧整合方式
Most people like
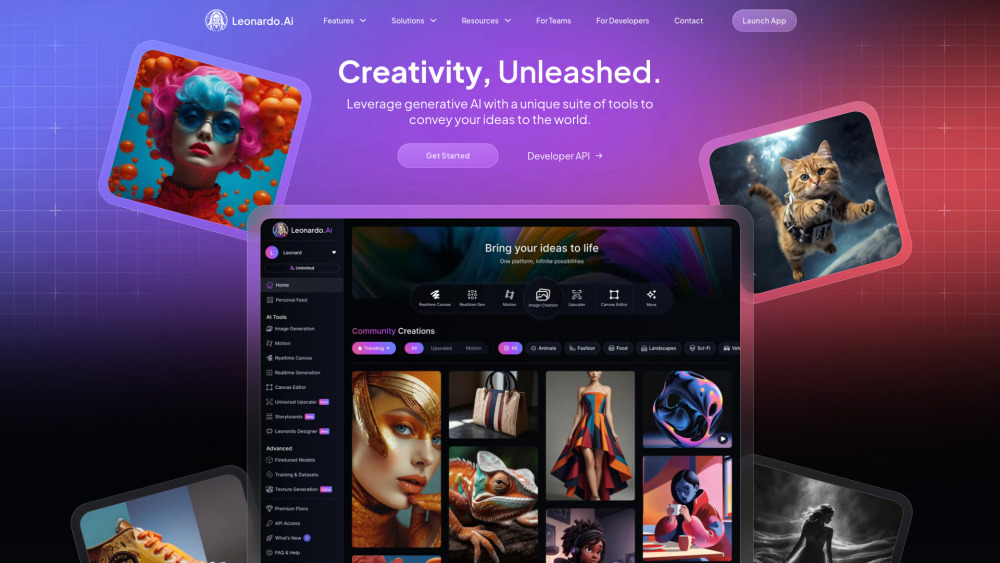
透過利用人工智慧圖像與視頻生成的力量,釋放您創意工作的潛力。這項創新技術使藝術家、行銷專業人士和內容創作者能夠輕鬆製作驚豔的視覺效果和動態影片。探索人工智慧如何提升您的專案,增強您的敘事,並前所未有地吸引您的觀眾。
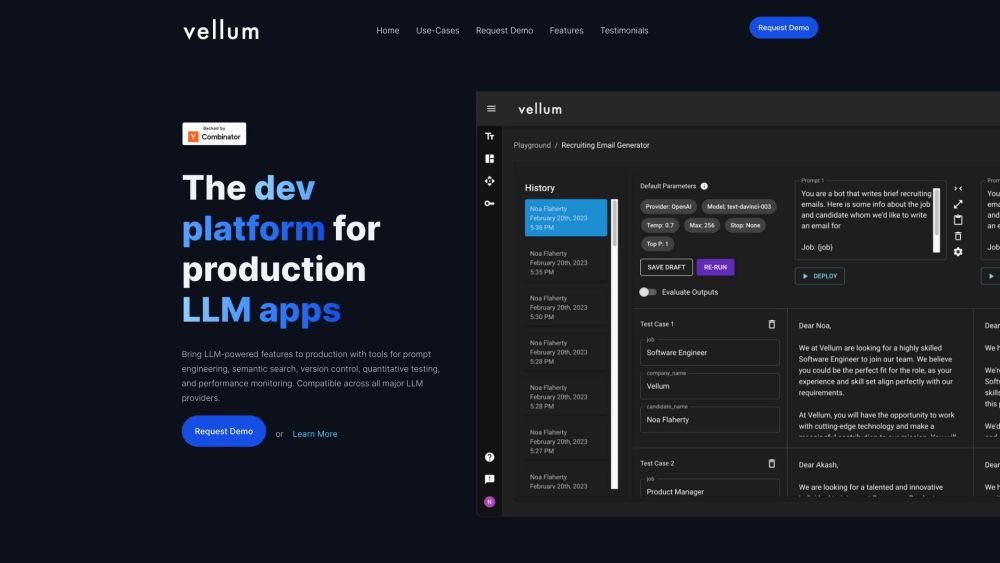
介紹一個專為創建大型語言模型(LLM)應用而設計的先進開發平台。這個創新平台簡化了開發過程,為開發者提供所需的工具和資源,以高效地構建、測試和部署強大的LLM驅動解決方案。無論您是經驗豐富的開發者還是剛起步的新手,我們的平台都提供靈活性和支持,幫助您將AI理念變為現實。和我們一起顛覆LLM應用的開發方式吧!
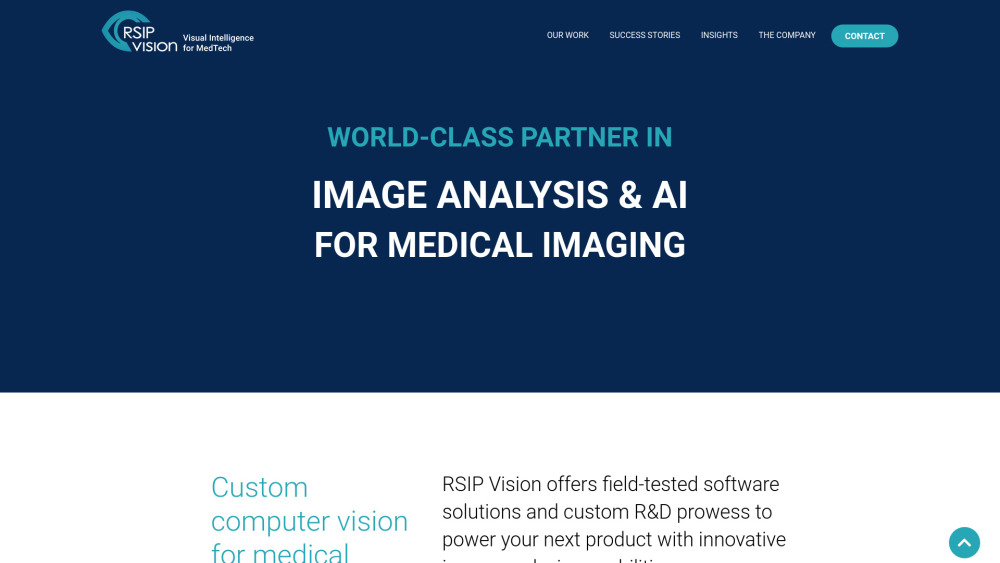
在當今迅速演變的醫療保健領域,醫學影像分析與人工智慧(AI)的交匯正在徹底改變診斷與治療計畫。作為該領域的領導者,我們致力於透過先進的影像技術和AI驅動的洞見提升病患的療效。我們的創新努力不僅在技術上取得進展,更重新定義了醫學的護理標準,使我們成為精準醫療探索中的基石。深入了解我們開創性的創新如何塑造醫學影像的未來,並推動醫療系統的效率。
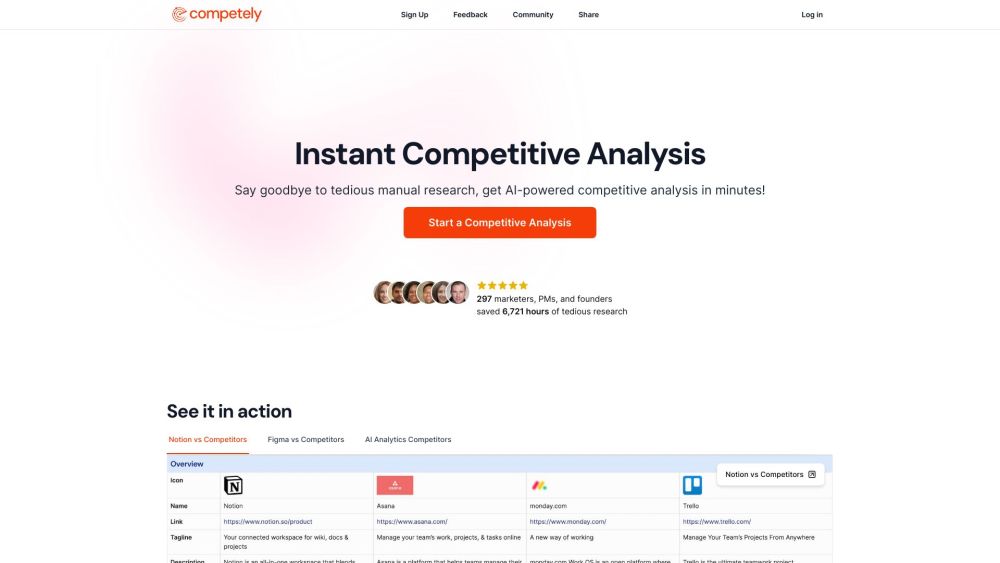
Find AI tools in YBX
Related Articles

Refresh Articles