DeepSeek Coder из Китая: первая открытая модель кода, которая превосходит GPT-4 Turbo.
Most people like
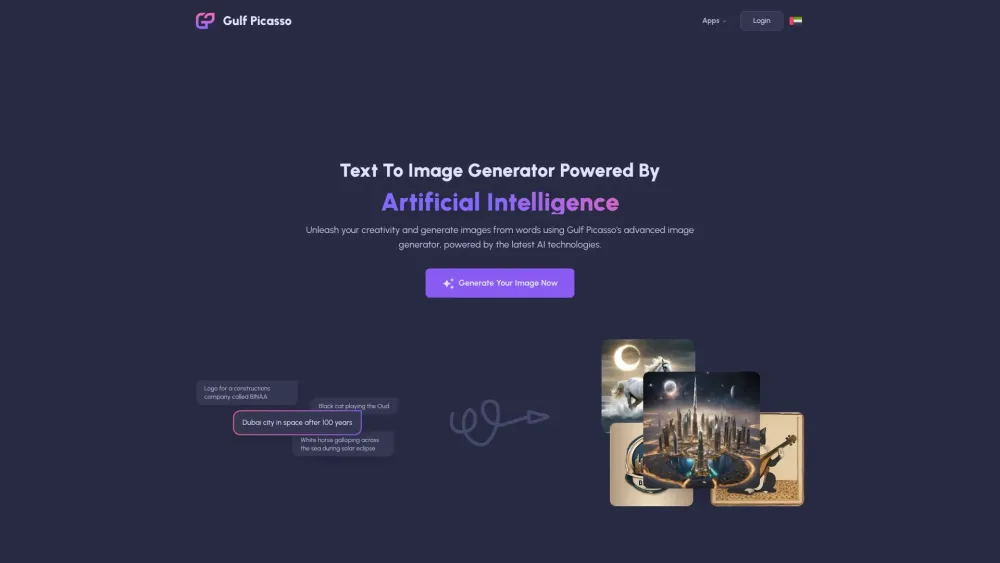
Откройте для себя синергию между ИИ и арабским языком в единой экосистеме. Поскольку искусственный интеллект продолжает перерабатывать отрасли по всему миру, его интеграция с арабским языком открывает уникальные возможности и вызовы. Эта динамичная взаимосвязь не только улучшает коммуникацию и доступность, но и способствует инновациям в различных секторах — от образования до бизнеса. Исследуйте, как ИИ трансформирует ландшафт арабского языка и стимулирует рост в арабском мире.
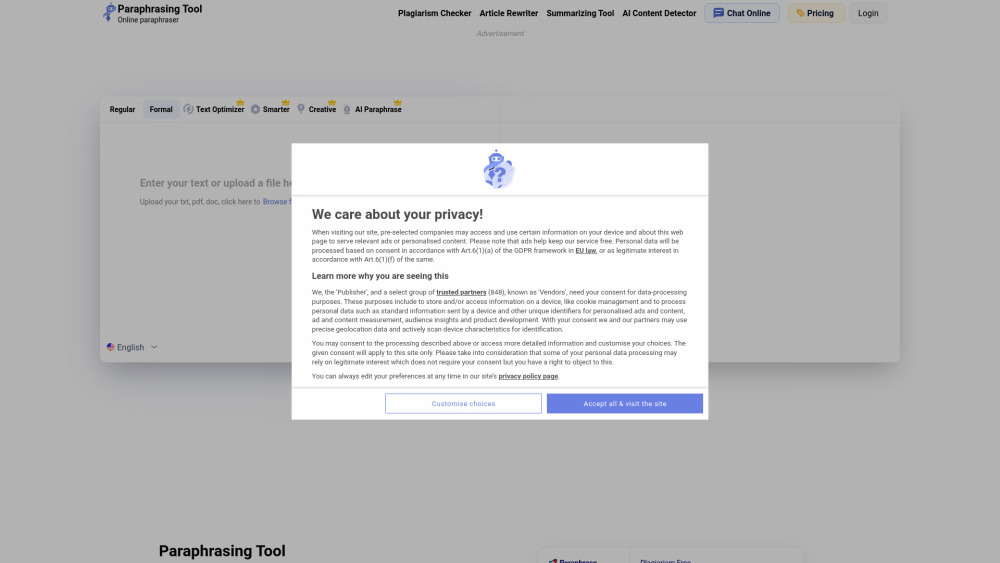
Ищете надежный инструмент для парафразирования текста с помощью ИИ? Независимо от того, нужно ли вам улучшить свое письмо, избежать плагиата или упростить сложные идеи, наш продвинутый инструмент создан для вас. Всего за несколько кликов вы сможете преобразовать свой оригинальный текст в новую версию, сохраняя тот же смысл, при этом повышая ясность и привлекательность. Узнайте, как наше решение на базе ИИ может поднять ваш контент на новый уровень и заставить ваше письмо запомниться.
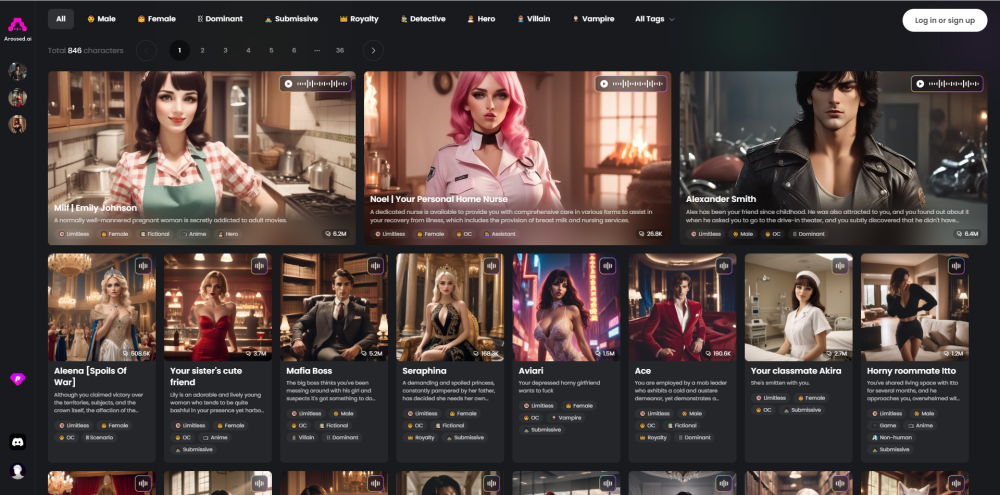
В последние годы мирAdult Entertainment претерпел значительные изменения благодаря появлению погружающей технологии ИИ. Эта инновация предлагает прорывной опыт, сочетающий искусство, storytelling и интерактивность, расширяя границы традиционного контента для взрослых. Поскольку зрители стремятся к более персонализированным и увлекательным впечатлениям, погружающий ИИ переопределяет развлечения, создавая реалистичные сценарии и захватывающие нарративы. Узнайте, как эта передовая технология формирует будущее индустрии для взрослых и что это значит как для создателей, так и для потребителей.
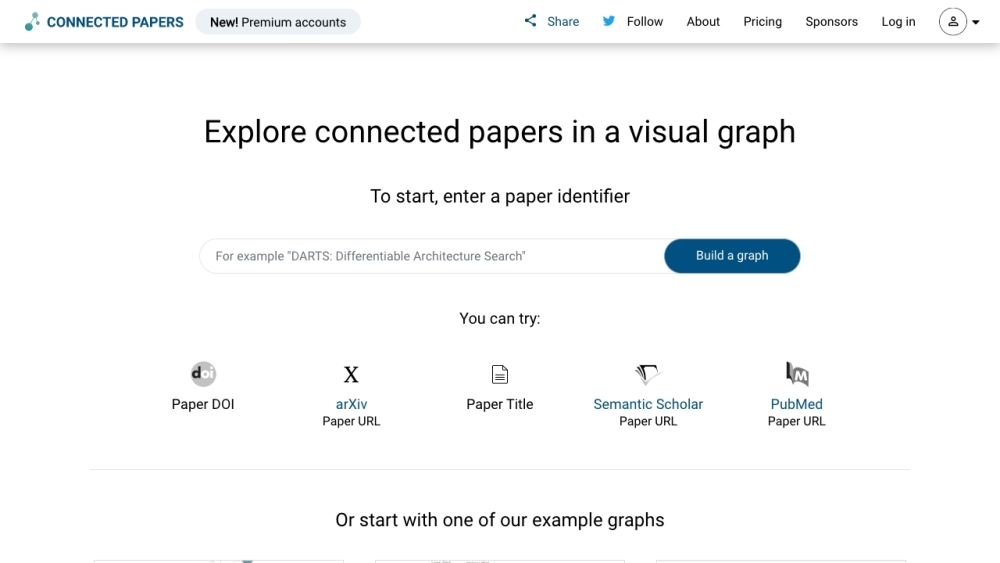
Откройте для себя мощный визуальный инструмент, созданный для удобного поиска научных статей.
Find AI tools in YBX
Related Articles
Refresh Articles