Google Debuts Advanced Video, Image, and Music Models at Google I/O 2024
Most people like
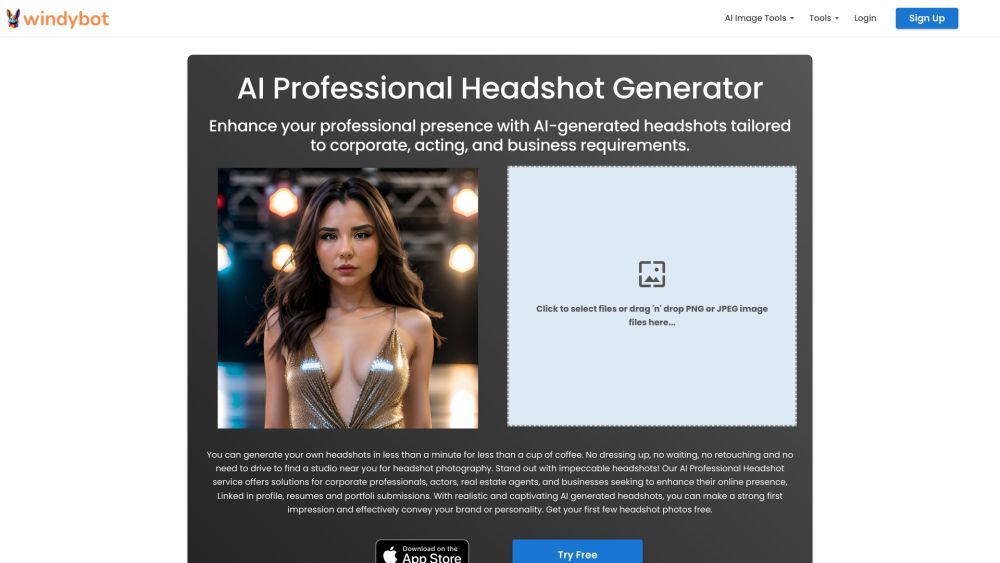
In today’s digital landscape, striking visuals are essential for capturing attention and conveying your brand's message. With advancements in technology, AI tools for professional image enhancement have emerged as powerful resources to refine and elevate your photography. These innovative solutions enable users to effortlessly adjust lighting, colors, and details, ensuring each image stands out. Whether you're a photographer, marketer, or content creator, leveraging AI for image enhancement can dramatically improve the quality of your visual content and engage your audience more effectively.

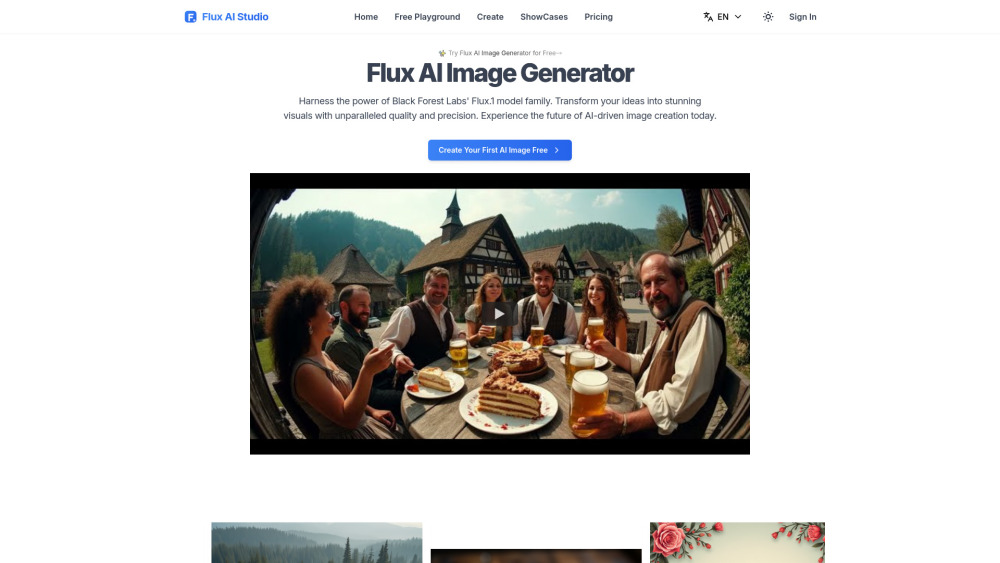
Discover our AI-powered platform that transforms your text into stunning images. With advanced technology, you can effortlessly bring your words to life—creating visuals to match your imagination. Join countless users who have unlocked the potential of turning ideas into captivating graphics using our innovative tools.
Introducing an innovative AI-powered music creation platform designed to revolutionize how you compose and produce music. This cutting-edge tool harnesses the power of artificial intelligence to streamline the creative process, providing musicians of all levels with instant inspiration and unique compositions. Unlock your musical potential and explore endless possibilities with our user-friendly platform that combines technology and artistry seamlessly. Whether you’re a seasoned professional or just starting out, our AI music creator will elevate your sound and enhance your workflow. Join the future of music creation today!
Find AI tools in YBX
Related Articles


Refresh Articles